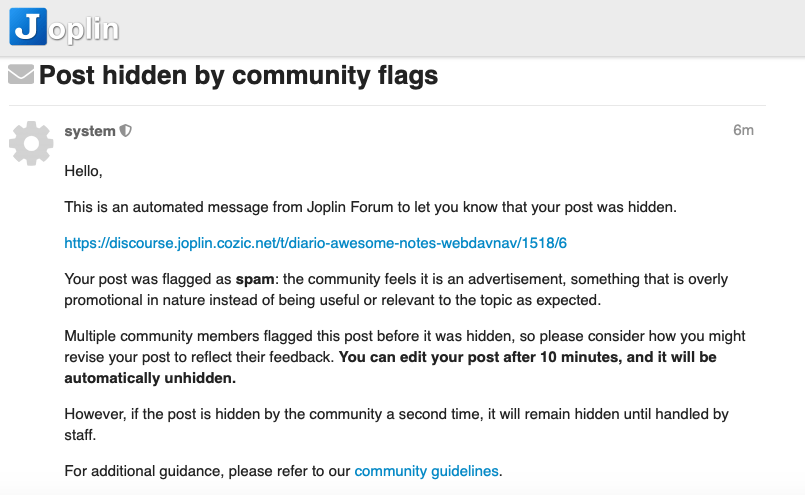
(See the finale release : https://www.cyber-neurones.org/2019/02/diaro-app-pixel-crater-ltd-diarobackup-xml-how-to-migrate-data-to-joplin/ )
Step 1: Add in first ligne : <?xml version= »1.0″ encoding= »UTF-8″?> before <data> in file DiaroBackup.xml … it’s mandatory !
I use REST API to insert in JOPLIN : https://joplin.cozic.net/api/ , it’s good documentation.
Here my first release in Python to import data from Diaro App Backup to Joplin API :
#
# Version 1
#
# ARIAS Frederic
# Sorry ... It's difficult for me the python :)
from urllib2 import unquote
from lxml import etree
import os
from time import gmtime, strftime
import time
strftime("%Y-%m-%d %H:%M:%S", gmtime())
start = time.time()
print("Start : Parse Table")
tree = etree.parse("./DiaroBackup.xml")
for table in tree.xpath("/data/table"):
print(table.get("name"))
print("End : Parse Table")
#Token
ip = "127.0.0.1"
port = "41184"
#token = "ABCD123ABCD123ABCD123ABCD123ABCD123"
token = "blablabla"
cmd = 'curl http://'+ip+':'+port+'/notes?token='+token
print cmd
os.system(cmd)
#Init
Diaro_UID = "12345678901234567801234567890123"
Lat = {}
Lng = {}
Lat[""] = ""
Lng[""] = ""
cmd = 'curl --data \'{ "id": "'+Diaro_UID+'", "title": "Diaro Import"}\' http://'+ip+':'+port+'/folders?token='+token
print cmd
os.system(cmd)
print("Start : Parse Table")
tree = etree.parse("./DiaroBackup.xml")
for table in tree.iter('table'):
name = table.attrib.get('name')
print name
myorder = 1
for r in table.iter('r'):
myuid = ""
mytitle = ""
mylat = ""
mylng = ""
mytags = ""
mydate = ""
mytext = ""
myfilename = ""
myfolder_uid = Diaro_UID
mylocation_uid = ""
myprimary_photo_uid = ""
myentry_uid = ""
myorder += 1
for subelem in r:
print(subelem.tag)
if (subelem.tag == 'uid'):
myuid = subelem.text
print ("myuid",myuid)
if (subelem.tag == 'entry_uid'):
myentry_uid = subelem.text
print ("myentry_uid",myentry_uid)
if (subelem.tag == 'primary_photo_uid'):
myprimary_photo_uid = subelem.text
print ("myprimary_photo_uid",myprimary_photo_uid)
if (subelem.tag == 'folder_uid'):
myfolder_uid = subelem.text
print ("myfolder_uid",myfolder_uid)
if (subelem.tag == 'location_uid'):
mylocation_uid = subelem.text
print ("mylocation_uid",mylocation_uid)
if (subelem.tag == 'date'):
mydate = subelem.text
print ("mydate",mydate)
if (subelem.tag == 'title'):
mytitle = subelem.text
print ("mytitle",mytitle)
print type(mytitle)
if type(mytitle) == unicode:
mytitle = mytitle.encode('utf8')
if (subelem.tag == 'lat'):
mylat = subelem.text
print ("mylat",mylat)
if (subelem.tag == 'lng'):
mylng = subelem.text
print ("mylng",mylng)
if (subelem.tag == 'tags'):
mytags = subelem.text
if mytags:
mytags[1:]
print ("mytags",mytags)
if (subelem.tag == 'text'):
mytext = subelem.text
print ("mytext",mytext)
if type(mytext) == unicode:
mytext = mytext.encode('utf8')
if (subelem.tag == 'filename'):
myfilename = subelem.text
print ("myfilename",myfilename)
if (name == 'diaro_folders'):
cmd = 'curl --data \'{ "id": "'+myuid+'", "title": "'+mytitle+'", "parent_id": "'+Diaro_UID+'"}\' http://'+ip+':'+port+'/folders?token='+token
print cmd
os.system(cmd)
if (name == 'diaro_tags'):
cmd = 'curl --data \'{ "id": "'+myuid+'", "title": "'+mytitle+'"}\' http://'+ip+':'+port+'/tags?token='+token
print cmd
os.system(cmd)
if (name == 'diaro_attachments'):
cmd = 'curl -F \'data=@media/photo/'+myfilename+'\' -F \'props={"id":"'+myuid+'"}\' http://'+ip+':'+port+'/resources?token='+token
print cmd
os.system(cmd)
cmd = 'curl -X PUT http://'+ip+':'+port+'/resources/'+myuid+'/notes/'+myentry_uid+'?token='+token
print cmd
os.system(cmd)
if (name == 'diaro_locations'):
Lat[myuid] = mylat
Lng[myuid] = mylng
if (name == 'diaro_entries'):
if not mytext:
mytext = ""
if not myfolder_uid:
myfolder_uid = Diaro_UID
if not mytags:
mytags = ""
if not mylocation_uid:
mylocation_uid = ""
mytext = mytext.replace("'", "")
mytitle = mytitle.replace("'", "")
mytext = mytext.strip("\'")
mytitle = mytitle.strip("\'")
mytext = mytext.strip('(')
mytitle = mytitle.strip('(')
print type(mytext)
cmd = 'curl --data \'{"latitude":"'+Lat[mylocation_uid]+'","longitude":"'+Lng[mylocation_uid]+'","tags":"'+mytags+'","parent_id":"'+myfolder_uid+'","id":"'+myuid+'","title":"'+mytitle+'", "created_time": "'+mydate+'", "body": "'+mytext+'"}\' http://'+ip+':'+port+'/notes?token='+token
print cmd
os.system(cmd)
print("End : Parse Table")
strftime("%Y-%m-%d %H:%M:%S", gmtime())
done = time.time()
elapsed = done - start
print(elapsed)But I don’t understand the API, I can force the id ( for exemple : 12345678901234567801234567890123 ):
curl --data '{ "id": "12345678901234567801234567890123", "title": "Diaro Import"}' http://127.0.0.1:41184/folders?token=.....
{"title":"Diaro Import","id":"73d15fe0b55e40dabea353b0f9d45547","updated_time":1549406274867,"created_time":1549406274867,"user_updated_time":1549406274867,"user_created_time":1549406274867,"type_":2}
Same issue with ressource :
curl -F 'data=@media/photo/photo_20181202_810728.jpg' -F 'props={"id":"fe2a86a78bded44f18d6da73fff9a3e1"}' http://127.0.0.1:41184/resources?token=.....
{"id":"68d662d3b7f0421f9dc4bf8f33bdc74c","title":"UpPr0WId4ZsIFiLAAL6ZLMf1.jpg","mime":"image/jpeg","filename":"","created_time":1549409257224,"updated_time":1549409257229,"user_created_time":1549409257224,"user_updated_time":1549409257229,"file_extension":"jpg","encryption_cipher_text":"","encryption_applied":0,"encryption_blob_encrypted":0,"type_":4}
And also all my notes are tags ?!
Logs of Joplin ( .config/joplin-desktop/log.txt ) , before import :
2019-02-05 23:25:51: "Running background sync on timer..."
2019-02-05 23:25:51: "Scheduling sync operation..."
2019-02-05 23:25:51: "Preparing scheduled sync"
2019-02-05 23:25:51: "Starting scheduled sync"
2019-02-05 23:25:51: "Operations completed: "
2019-02-05 23:25:51: "fetchingTotal: -"
2019-02-05 23:25:51: "Total folders: 8"
2019-02-05 23:25:51: "Total notes: 23"
2019-02-05 23:25:51: "Total resources: 35"Logs of Joplin, after import (no information on Tags):
2019-02-06 00:28:49: "Scheduling sync operation..."
2019-02-06 00:28:49: "Preparing scheduled sync"
2019-02-06 00:28:49: "Starting scheduled sync"
2019-02-06 00:28:49: "Operations completed: "
2019-02-06 00:28:49: "createRemote: 2"
2019-02-06 00:28:49: "fetchingTotal: 2"
2019-02-06 00:28:49: "Total folders: 24"
2019-02-06 00:28:49: "Total notes: 460"
2019-02-06 00:28:49: "Total resources: 891"
But I don’t see any notes … but the note are on tags ?!
How to start the API :
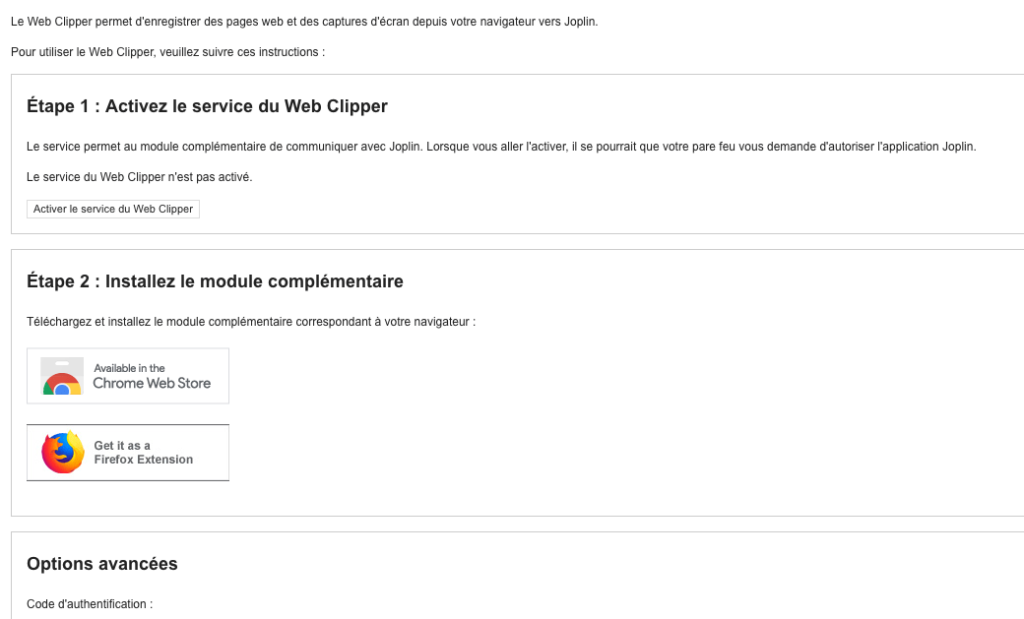
And when you active the service, you see the port :

And not easy to contact the forum : https://discourse.joplin.cozic.net/t/diario-awesome-notes-webdavnav/1518/6