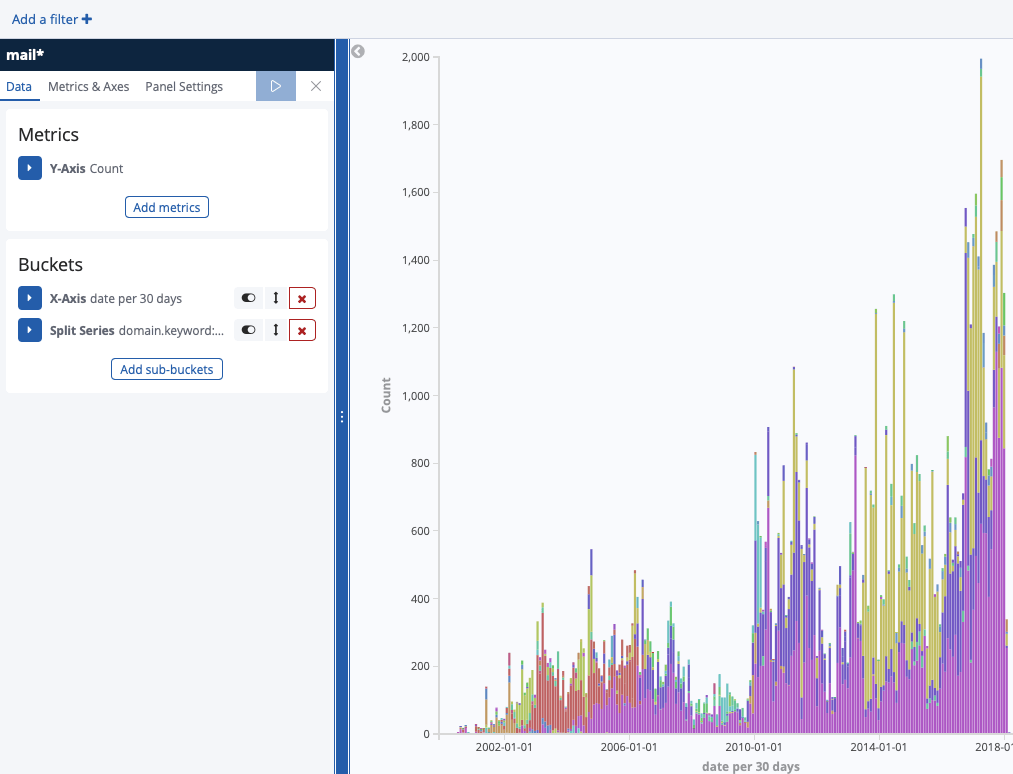
Petit script pour envoyer l’historique d’un SVN vers Elasticsearch/Kibana. Avant j’utilisais statSVN : https://statsvn.org .
Pour l’installation sous Mac :
$ pip2 install --upgrade pip $ pip2 install elasticsearch
Voici le programme :
import xml.etree.ElementTree as ET
import os
import re
from elasticsearch import Elasticsearch
import sys
tree = ET.parse('svn.log')
root = tree.getroot()
count = 0;
nb_error = 0
es=Elasticsearch([{'host':'localhost','port':9200}])
es_keys="svn"
for logentry in root.iter('logentry'):
revision = logentry.get('revision')
author = logentry.find('author').text
date = logentry.find('date').text
msg = logentry.find('msg').text
if msg is not None:
msg = msg.replace("\n", " ")
msg = msg.replace("\r", " ")
msg = msg.rstrip('\r\n')
msg = msg.strip('\r\n')
msg = str(re.sub(r'[^\x00-\x7F]',' ', msg))
paths = logentry.find('paths')
for path in paths.findall('path'):
my_path = path.text
my_basename = os.path.basename(my_path)
my_dir = os.path.dirname(my_path)
count += 1
if msg is not None:
json = '{"revision":'+revision+',"author":"'+author+'","date":"'+date+'","msg":"'+msg+'","basename":"'+my_basename+'","folder":"'+my_dir+'"}'
else:
json = '{"revision":'+revision+',"author":"'+author+'","date":"'+date+'","basename":"'+my_basename+'","folder":"'+my_dir+'"}'
print(count,json)
try:
res = es.index(index=es_keys,doc_type='svn',id=count,body=json)
except:
nb_error += 1
Il faut faire un export XML de SVN :
$ svn log -v --xml > svn.log
Pour faire le check : http://127.0.0.1:9200/svn/_mappings , la réponse est du type :
{"svn":{"mappings":{"svn":{"properties":{"author":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"basename":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"date":{"type":"date"},"folder":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"msg":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"revision":{"type":"long"}}}}}}