J’ai trouvé un outil de test de llm : llm_benchmark ( installation via pip )
Je suis en dernière position : https://llm.aidatatools.com/results-linux.php , avec « llama3.1:8b »: « 1.12 ».

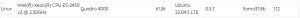
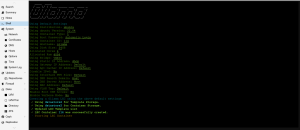
llm_benchmark run
-------Linux----------
{'id': '0', 'name': 'Quadro 4000', 'driver': '390.157', 'gpu_memory_total': '1985.0 MB',
'gpu_memory_free': '1984.0 MB', 'gpu_memory_used': '1.0 MB', 'gpu_load': '0.0%',
'gpu_temperature': '60.0°C'}
Only one GPU card
Total memory size : 61.36 GB
cpu_info: Intel(R) Xeon(R) CPU E5-2450 v2 @ 2.50GHz
gpu_info: Quadro 4000
os_version: Ubuntu 22.04.5 LTS
ollama_version: 0.5.7
----------
LLM models file path:/usr/local/lib/python3.10/dist-packages/llm_benchmark/data/benchmark_models_16gb_ram.yml
Checking and pulling the following LLM models
phi4:14b
qwen2:7b
gemma2:9b
mistral:7b
llama3.1:8b
llava:7b
llava:13b
----------
....
----------------------------------------
Sending the following data to a remote server
-------Linux----------
{'id': '0', 'name': 'Quadro 4000', 'driver': '390.157', 'gpu_memory_total': '1985.0 MB',
'gpu_memory_free': '1984.0 MB', 'gpu_memory_used': '1.0 MB', 'gpu_load': '0.0%',
'gpu_temperature': '61.0°C'}
Only one GPU card
-------Linux----------
{'id': '0', 'name': 'Quadro 4000', 'driver': '390.157', 'gpu_memory_total': '1985.0 MB',
'gpu_memory_free': '1984.0 MB', 'gpu_memory_used': '1.0 MB', 'gpu_load': '0.0%',
'gpu_temperature': '61.0°C'}
Only one GPU card
{
"mistral:7b": "1.40",
"llama3.1:8b": "1.12",
"phi4:14b": "0.76",
"qwen2:7b": "1.31",
"gemma2:9b": "1.03",
"llava:7b": "1.84",
"llava:13b": "0.73",
"uuid": "",
"ollama_version": "0.5.7"
}
----------