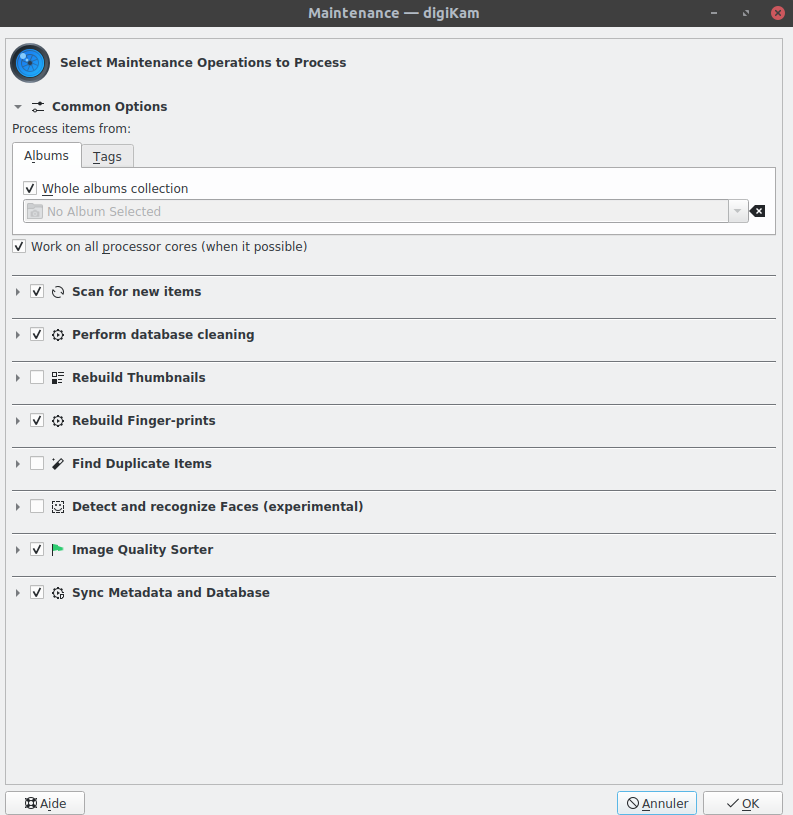
J’ai fait une petite lecture des tables de Dikikam afin de faire un export des images similaires avec un taux à 1.0 :
$ sqlite3
SQLite version 3.22.0 2018-01-22 18:45:57
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> .open similarity.db
sqlite> .tables
ImageHaarMatrix ImageSimilarity SimilaritySettings
sqlite> .schema ImageSimilarity
CREATE TABLE ImageSimilarity
(imageid1 INTEGER NOT NULL,
imageid2 INTEGER NOT NULL,
algorithm INTEGER,
value DOUBLE,
CONSTRAINT Similar UNIQUE(imageid1, imageid2, algorithm));
sqlite> .schema ImageHaarMatrix
CREATE TABLE ImageHaarMatrix
(imageid INTEGER PRIMARY KEY,
modificationDate DATETIME,
uniqueHash TEXT,
matrix BLOB);
CREATE TRIGGER delete_similarities DELETE ON ImageHaarMatrix
BEGIN
DELETE FROM ImageSimilarity
WHERE ( ImageSimilarity.imageid1=OLD.imageid OR ImageSimilarity.imageid2=OLD.imageid )
AND ( ImageSimilarity.algorithm=1 );
END;
sqlite> .schema SimilaritySettings
CREATE TABLE SimilaritySettings
(keyword TEXT NOT NULL UNIQUE,
value TEXT);
sqlite> .open digikam4.db
sqlite> .tables
AlbumRoots ImageHistory ImageRelations Settings
Albums ImageInformation ImageTagProperties TagProperties
DownloadHistory ImageMetadata ImageTags Tags
ImageComments ImagePositions Images TagsTree
ImageCopyright ImageProperties Searches VideoMetadata
sqlite> .schema Images
CREATE TABLE Images
(id INTEGER PRIMARY KEY,
album INTEGER,
name TEXT NOT NULL,
status INTEGER NOT NULL,
category INTEGER NOT NULL,
modificationDate DATETIME,
fileSize INTEGER,
uniqueHash TEXT,
manualOrder INTEGER,
UNIQUE (album, name));
CREATE INDEX dir_index ON Images (album);
CREATE INDEX hash_index ON Images (uniqueHash);
CREATE INDEX image_name_index ON Images (name);
CREATE TRIGGER delete_image DELETE ON Images
BEGIN
DELETE FROM ImageTags WHERE imageid=OLD.id;
DELETE From ImageInformation WHERE imageid=OLD.id;
DELETE From ImageMetadata WHERE imageid=OLD.id;
DELETE From VideoMetadata WHERE imageid=OLD.id;
DELETE From ImagePositions WHERE imageid=OLD.id;
DELETE From ImageComments WHERE imageid=OLD.id;
DELETE From ImageCopyright WHERE imageid=OLD.id;
DELETE From ImageProperties WHERE imageid=OLD.id;
DELETE From ImageHistory WHERE imageid=OLD.id;
DELETE FROM ImageRelations WHERE subject=OLD.id OR object=OLD.id;
DELETE FROM ImageTagProperties WHERE imageid=OLD.id;
UPDATE Albums SET icon=null WHERE icon=OLD.id;
UPDATE Tags SET icon=null WHERE icon=OLD.id;
END;
sqlite> .schema ImageInformation
CREATE TABLE ImageInformation
(imageid INTEGER PRIMARY KEY,
rating INTEGER,
creationDate DATETIME,
digitizationDate DATETIME,
orientation INTEGER,
width INTEGER,
height INTEGER,
format TEXT,
colorDepth INTEGER,
colorModel INTEGER);
CREATE INDEX creationdate_index ON ImageInformation (creationDate);
sqlite> .schema Albums
CREATE TABLE Albums
(id INTEGER PRIMARY KEY,
albumRoot INTEGER NOT NULL,
relativePath TEXT NOT NULL,
date DATE,
caption TEXT,
collection TEXT,
icon INTEGER,
UNIQUE(albumRoot, relativePath));
CREATE TRIGGER delete_album DELETE ON Albums
BEGIN
DELETE FROM Images
WHERE Images.album = OLD.id;
END;
sqlite> attach 'digikam4.db' as db1;
sqlite> attach 'similarity.db' as db2;
sqlite> select count(*) from db1.Images as A, db2.ImageSimilarity as B, db1.Albums as C where B.imageid2 = A.id and B.algorithm = 1.0 and A.album = C.id;
36796
sqlite> select relativePath || '/' || name from db1.Images as A, db2.ImageSimilarity as B, db1.Albums as C where B.imageid2 = A.id and B.algorithm = 1.0 and A.album = C.id group by relativePath;
...
sqlite> .output file_duplicate.txt
sqlite> select '.' || relativePath || '/' || name from db1.Images as A, db2.ImageSimilarity as B, db1.Albums as C where B.imageid2 = A.id and B.algorithm = 1.0 and A.album = C.id group by relativePath;
sqlite> select count(*) from db1.Images as A, db2.ImageSimilarity as B, db1.Albums as C where B.imageid2 = A.id and A.album = C.id and relativePath = '/2019/11/28';
654
sqlite> select count(*) from db1.Images as A, db2.ImageSimilarity as B, db1.Albums as C where B.imageid1 = A.id and A.album = C.id and relativePath = '/2019/11/28';
2545
sqlite> .output file_duplicate_2.txt
sqlite> select '.' || relativePath || '/' || name from db1.Images as A, db2.ImageSimilarity as B, db1.Albums as C where B.imageid2 = A.id and B.algorithm > 0.96 and A.album = C.id;
sqlite> .output file_duplicate_3.txt
sqlite> select '.' || relativePath || '/' || name from db1.Images as A, db2.ImageSimilarity as B, db1.Albums as C where B.imageid1 = A.id and B.algorithm > 0.96 and A.album = C.id;
sqlite> .quit
Ensuite pour la suppression j’ai fait :
$ cat file_duplicate_3.txt | sed 's/ /\\ /g' > file_duplicate_3_2.txt
...
$ xargs rm -r <file_duplicate_3_2.txt
...
$ wc -l file_duplicate_3_2.txt
37060 file_duplicate_3_2.txt
Ensuite je fini par :
$ time exiftool -v -r "-filemodifydate<datetimeoriginal" "-filecreateddate<datetimeoriginal" .
$ sortphotos -r . . --sort %Y/%m/%d
Et je relance Digikam pour lui refaire faire une analyse complète.
Quelle usine, mais cela fonctionne.
J’aime ça :
J’aime chargement…