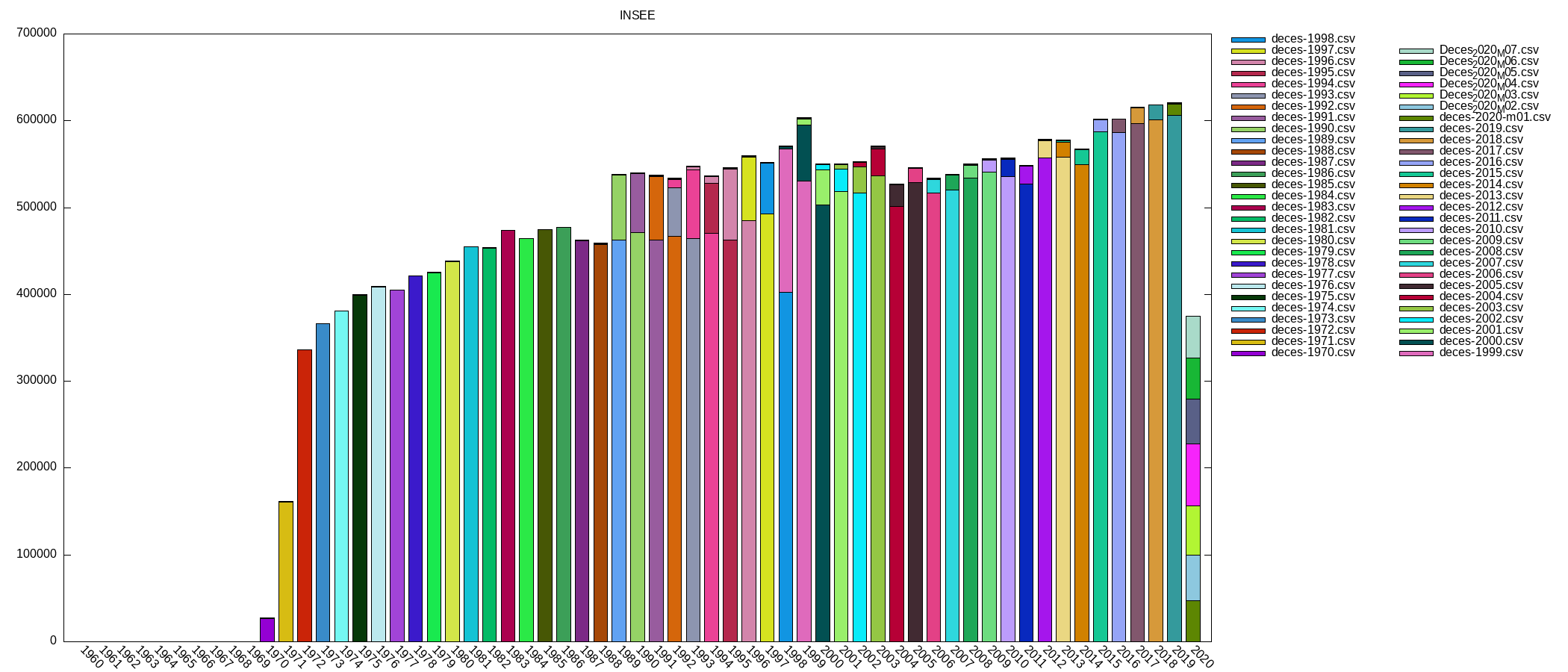
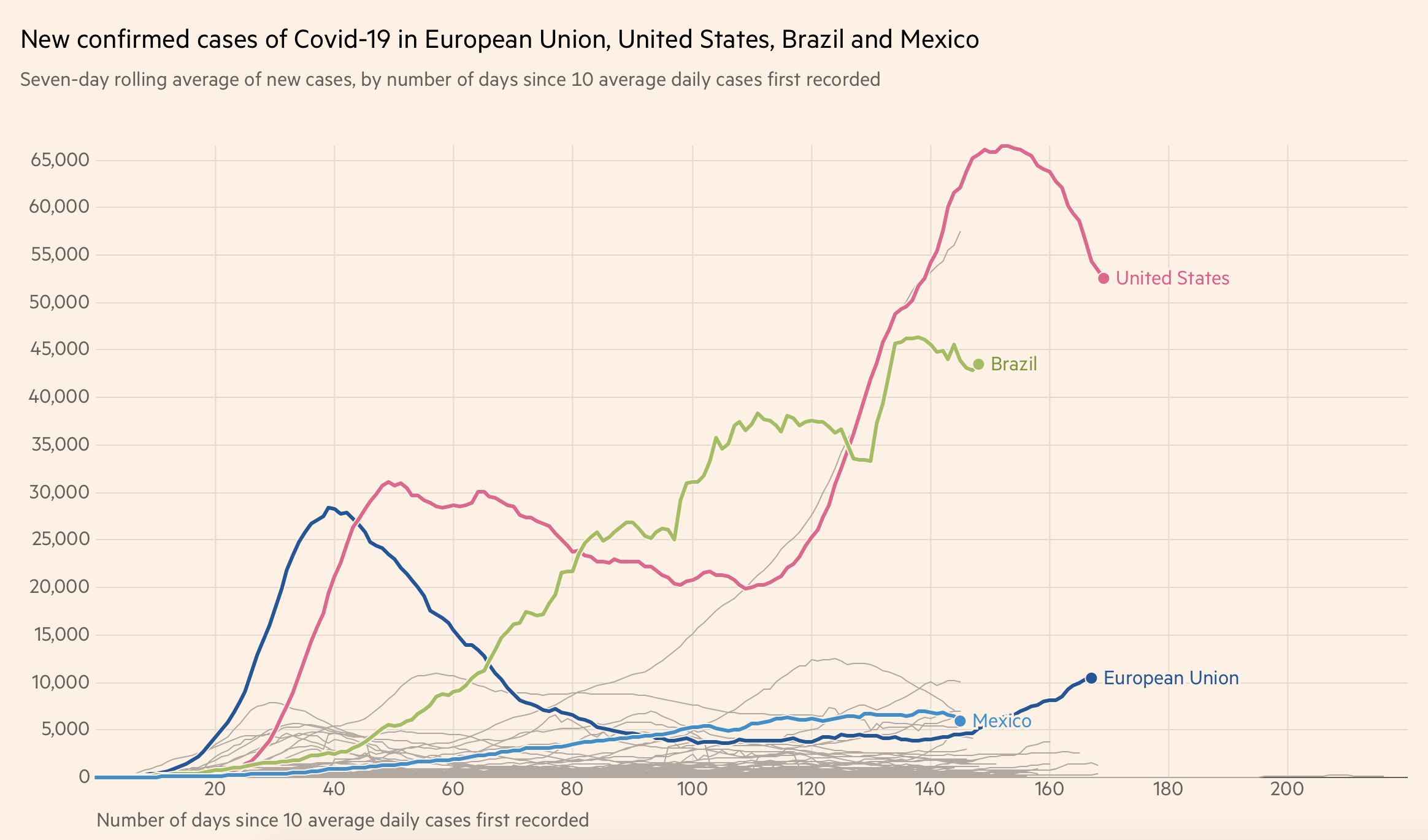
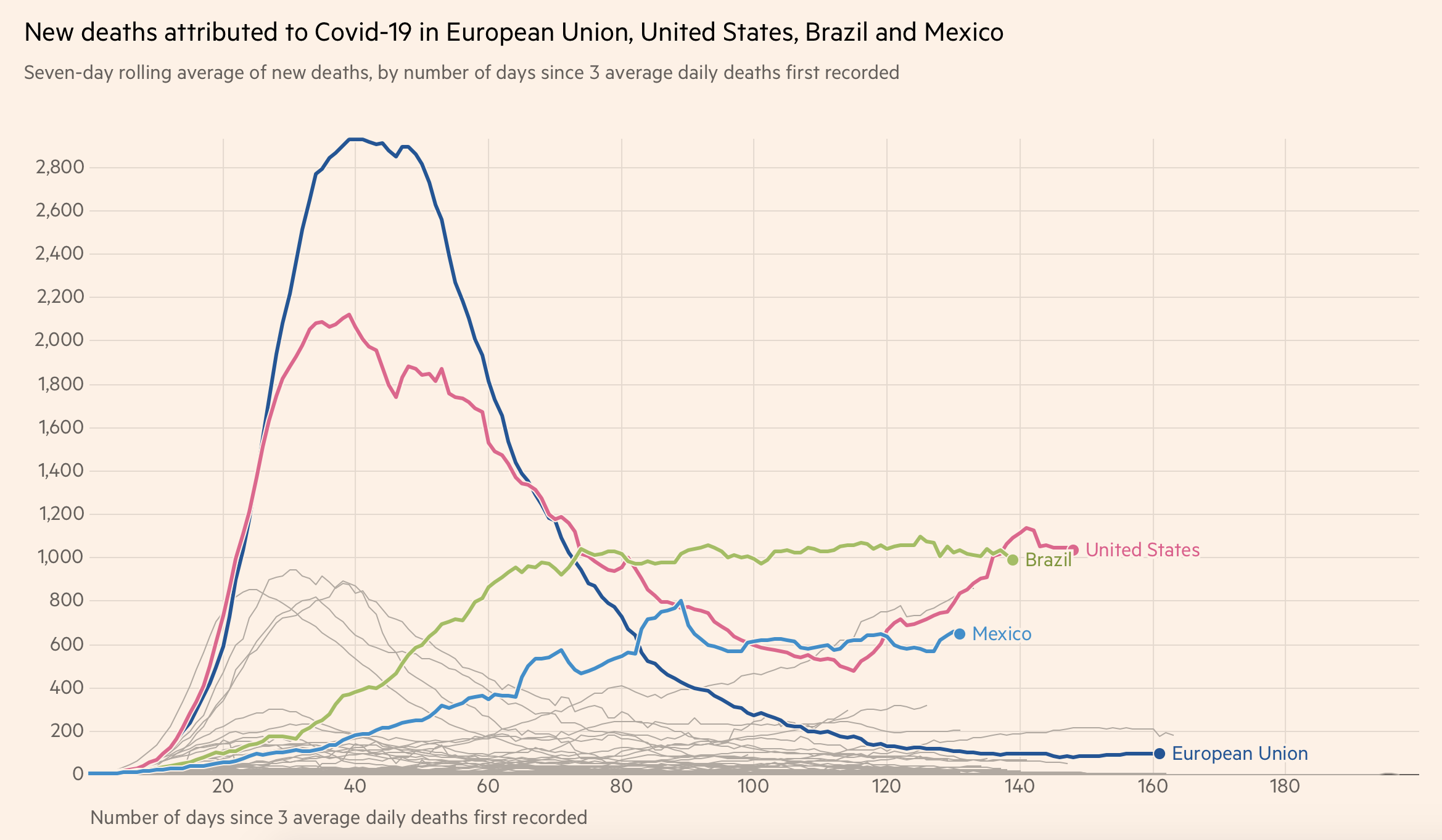
Le lien est ici : https://www.insee.fr/fr/information/4190491 . Je n’arrive pas à comprendre pourquoi les gens font des statistiques sur 2020 alors que la collecte des données est longue.
Quand je télécharge tous les fichiers et que je redirige sur un seul fichier j’ai :
wc -l *.csv
27007 deces-1970.csv
161020 deces-1971.csv
336009 deces-1972.csv
366041 deces-1973.csv
380603 deces-1974.csv
399310 deces-1975.csv
408884 deces-1976.csv
404775 deces-1977.csv
421033 deces-1978.csv
424987 deces-1979.csv
437857 deces-1980.csv
454545 deces-1981.csv
453263 deces-1982.csv
473523 deces-1983.csv
464104 deces-1984.csv
474632 deces-1985.csv
476864 deces-1986.csv
461802 deces-1987.csv
457905 deces-1988.csv
463082 deces-1989.csv
546888 deces-1990.csv
531676 deces-1991.csv
540833 deces-1992.csv
520435 deces-1993.csv
561327 deces-1994.csv
522052 deces-1995.csv
579008 deces-1996.csv
567669 deces-1997.csv
461461 deces-1998.csv
697193 deces-1999.csv
570495 deces-2000.csv
567112 deces-2001.csv
549494 deces-2002.csv
573623 deces-2003.csv
537817 deces-2004.csv
557036 deces-2005.csv
535114 deces-2006.csv
536333 deces-2007.csv
553113 deces-2008.csv
557242 deces-2009.csv
551016 deces-2010.csv
549116 deces-2011.csv
579983 deces-2012.csv
582619 deces-2013.csv
569446 deces-2014.csv
609628 deces-2015.csv
603320 deces-2016.csv
612927 deces-2017.csv
620124 deces-2018.csv
625373 deces-2019.csv
60585 deces-2020-m01.csv
53708 Deces_2020_M02.csv
57270 Deces_2020_M03.csv
70944 Deces_2020_M04.csv
52008 Deces_2020_M05.csv
47226 Deces_2020_M06.csv
48414 Deces_2020_M07.csv
47579 Deces_2020_M08.csv
25354453 total
Soit 25.354.453 lignes … je vais enfin pouvoir tester MySQL avec une grande base. A noter que je pense que les fichies sont incompléts , j’ai pas retrouvé le nom de mon grand père mort en 1985.
A noter aussi le décalage dans la collecte, un petit script :
rm list2.dat
touch list2.dat
upperlim=2020
echo "Years" >> list2.dat
for ((i=1960; i<=upperlim; i++)); do echo "$i" >> list2.dat
done
echo "Init done"
i=0
for entry in *.csv
do
echo "$entry"
echo "Years $entry" > list.dat
cat $entry | grep -v "sexe" | sed 's/""/"-"/g'| awk -F'\";\"' '{print substr($7,1, 4)}' | sort -n | uniq -c | awk '{print $2 " " $1}' | sort -n >> list.dat
join -a1 -e0 -11 -21 -oauto list2.dat list.dat > result.dat
cp result.dat list2.dat
let "i=i+1"
done
echo "Number of file $i"
cat result.dat | sed 's/ /\t/g' > result2.dat
Puis ensuite un petit graphique avec gnuplot :
set title "INSEE"
set key invert reverse Left outside
set key autotitle columnheader
set yrange [0:700000]
set auto x
unset xtics
set xtics nomirror rotate by -45 scale 0
set style data histogram
set style histogram rowstacked
set style fill solid border -1
set boxwidth 0.75
set terminal png size 2100,900; set output 'printme3.png';
rgb(r,g,b)=int(255*r)*65536+int(255*g)*256+int(255*b)
do for [i=1:58] {
myrand=rand(int(rand(0)*i*100)+i*100)
set style line i linecolor rgb rgb(rand(0),rand(0),rand(0))
}
plot 'result2.dat' using 2:xtic(1), for [i=3:58] '' using i ls i
On voit bien de décalage dans les fichiers …