Voici donc les graphiques :

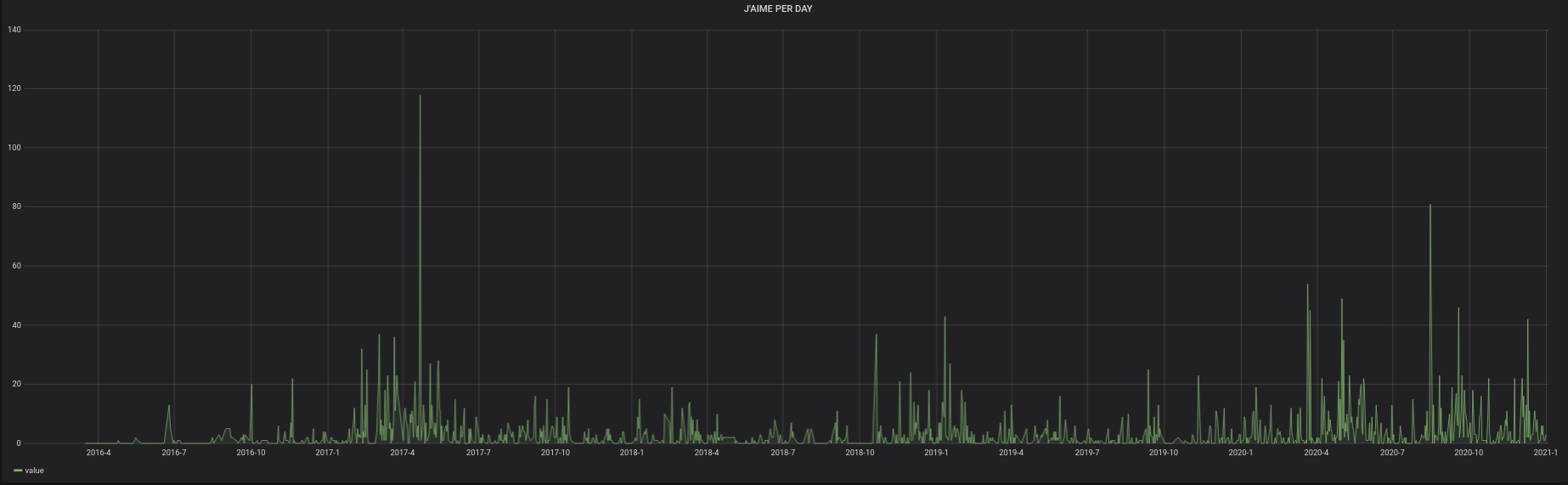
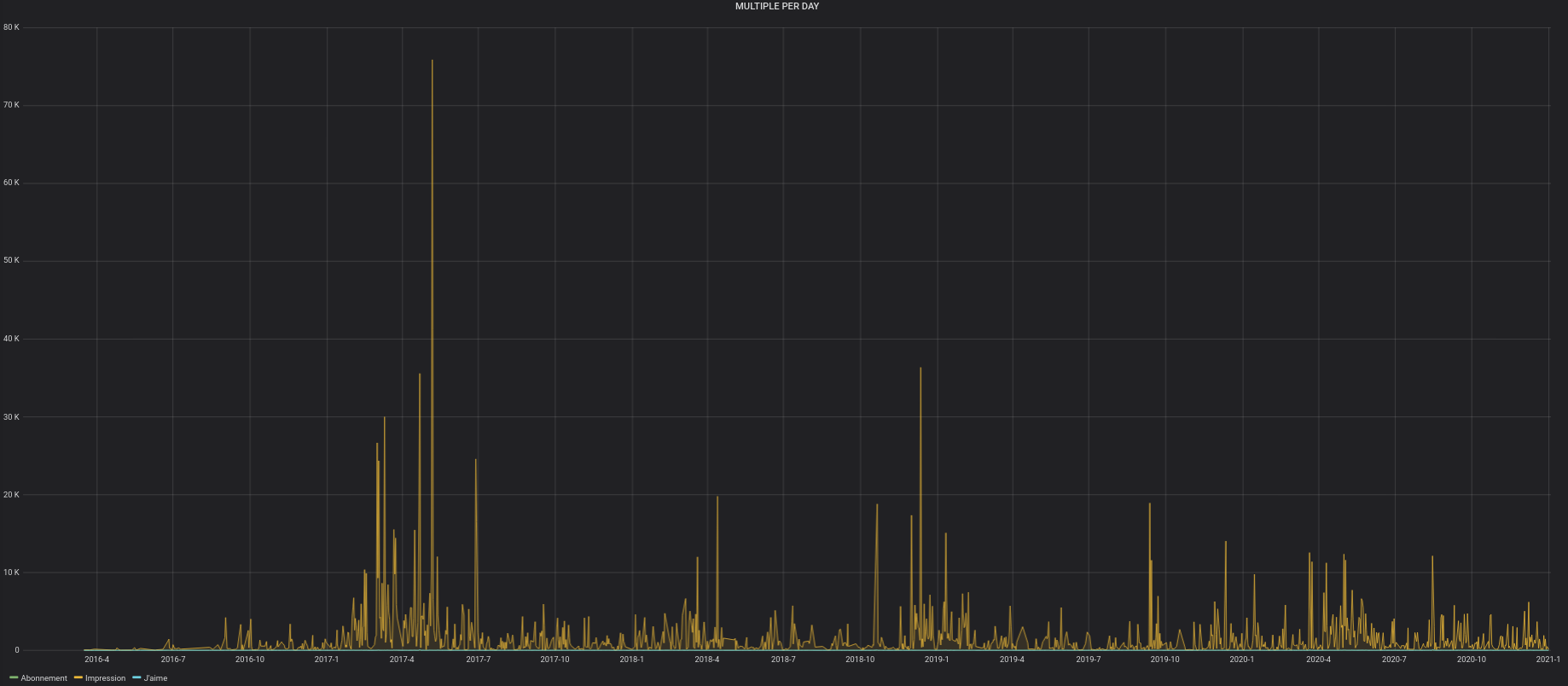

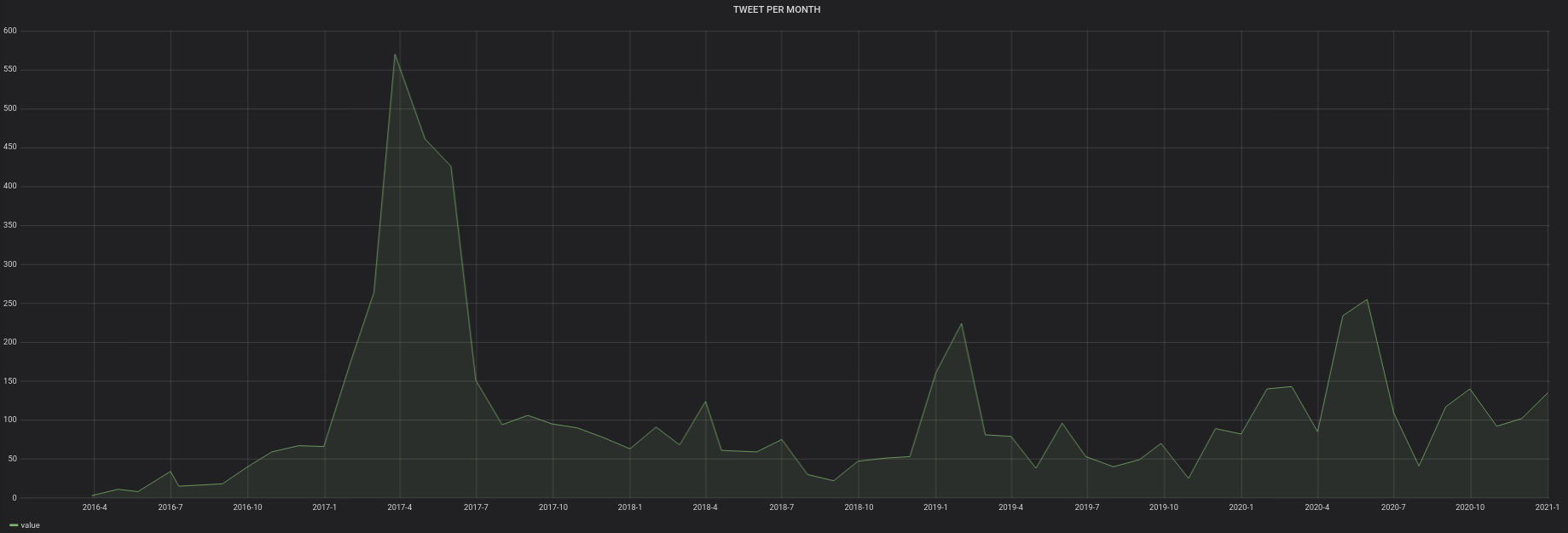
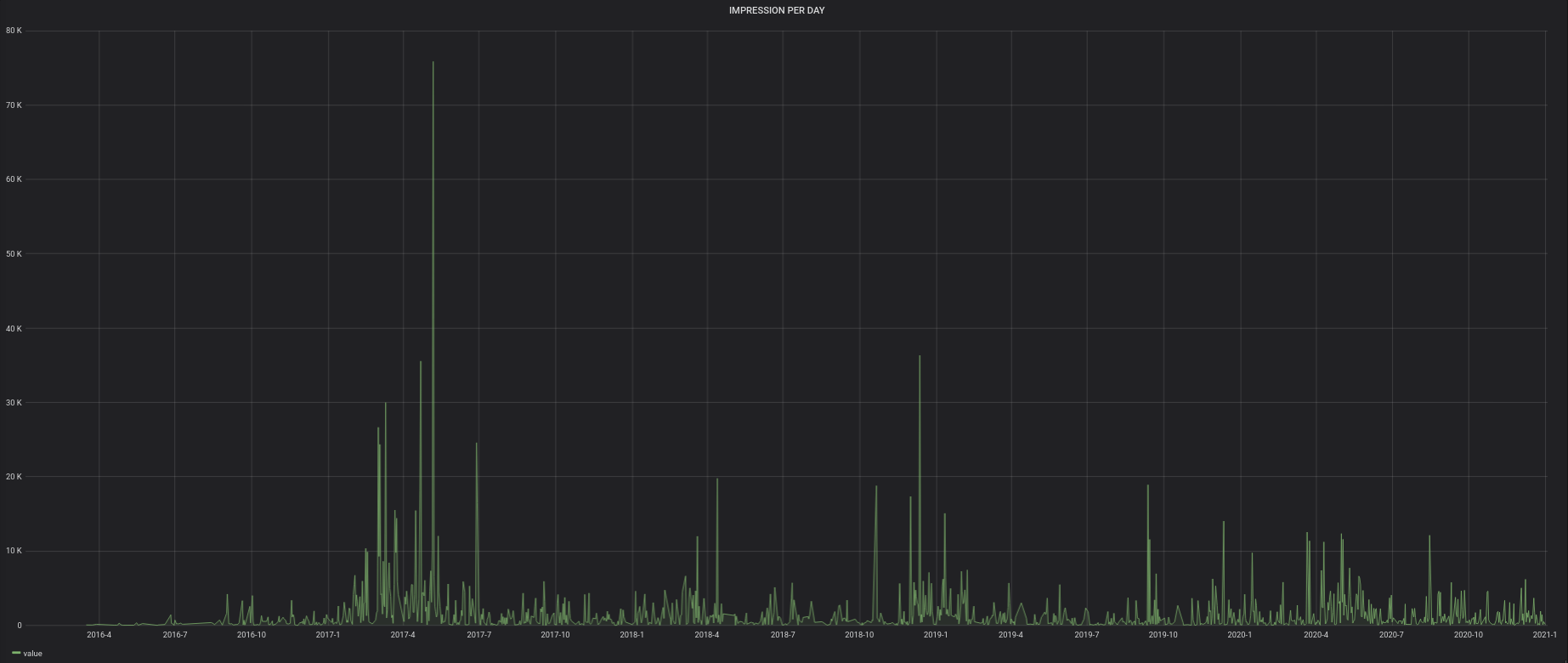
Le programme est en Python.

Voici donc les graphiques :
Le programme est en Python.
J’ai donc fait un nouveau graphique, du nombre de mort par tranche d’age avec les données de l’INSEE. (Tranche de 10 ans)
Le graphique est faux sur la fin 2020, il ne sera juste que vers mi-fevrier 2021. Quand l’INSEE aura publié les données.
Voici donc mon process :
Etape 1 : Téléchargement des données de l’INSEE : https://www.insee.fr/fr/information/4190491
Etape 2 : je mets tout sur un même fichier:
# cat deces-* Deces_2020_M* | grep -v "nomprenom" > Full.csv # wc -l Full.csv 25528867 Full.csv
Etape 3 : Je fais tourner un premier programme en Python :
# cat parse2.py
import csv
import datetime
from dateutil.relativedelta import relativedelta
with open('Full.csv', 'rt') as f:
csv_reader = csv.reader(f, quotechar='"', delimiter=';', quoting=csv.QUOTE_ALL, skipinitialspace=True)
for line in csv_reader:
#print(line[2])
if (len(line[2]) == 8) and (not (str(line[2]).endswith("00"))):
try:
start_date = datetime.datetime.strptime(line[2],"%Y%m%d");
except:
print("error1",line[2])
#print(line[6])
if (len(line[6]) == 8) and (not (str(line[6]).endswith("00"))):
try:
end_date = datetime.datetime.strptime(line[6],"%Y%m%d");
age = relativedelta(end_date, start_date).years
#print(line[6])
year = end_date.year
month = end_date.month
if age <= 10:
print year,",",month,", 0to10"
if 10 < age <= 20:
print year,",",month,", 10to20"
if 20 < age <= 30:
print year,",",month,", 20to30"
if 30 < age <= 40:
print year,",",month,", 30to40"
if 40 < age <= 50:
print year,",",month,", 40to50"
if 50 < age <= 60:
print year,",",month,", 50to60"
if 60 < age <= 70:
print year,",",month,", 60to70"
if 70 < age <= 80:
print year,",",month,", 70to80"
if 80 < age <= 90:
print year,",",month,", 80to90"
if 90 < age : print year,",",month,", more90" except: print("error2",line[6]) # python parse2.py > age2.csv
Etape 4 : J’ordonne et je fais le ménage (je garde que les année 20xx):
# cat clear.bash cat age2.csv | grep -v "error" | sort -n | uniq -c > sort-age2.csv echo "Date,Number" > 0to10.csv grep "0to10" sort-age2.csv | awk '{if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;} }' | grep "^20" | sort -n >> 0to10.csv echo "Date,Number" > 10to20.csv grep "10to20" sort-age2.csv | awk '{if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;} }' | grep "^20" | sort -n >> 10to20.csv echo "Date,Number" > 20to30.csv grep "20to30" sort-age2.csv | awk '{if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;} }' | grep "^20" | sort -n >> 20to30.csv echo "Date,Number" > 30to40.csv grep "30to40" sort-age2.csv | awk '{if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;} }' | grep "^20" | sort -n >> 30to40.csv echo "Date,Number" > 40to50.csv grep "40to50" sort-age2.csv | awk '{if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;} }' | grep "^20" | sort -n >> 40to50.csv echo "Date,Number" > 50to60.csv grep "50to60" sort-age2.csv | awk '{if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;} }' | grep "^20" | sort -n >> 50to60.csv echo "Date,Number" > 60to70.csv grep "60to70" sort-age2.csv | awk '{if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;} }' | grep "^20" | sort -n >> 60to70.csv echo "Date,Number" > 70to80.csv grep "70to80" sort-age2.csv | awk '{if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;} }' | grep "^20" | sort -n >> 70to80.csv echo "Date,Number" > 80to90.csv grep "80to90" sort-age2.csv | awk '{if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;} }' | grep "^20" | sort -n >> 80to90.csv echo "Date,Number" > more90.csv grep "more90" sort-age2.csv | awk '{if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;} }' | grep "^20" | sort -n >> more90.csv # ./clear.bash
Ou bien je garde uniquement > 1975 avec clear2.bash
cat clear2.bash
cat age2.csv | grep -v "error" | sort -n | uniq -c > sort-age2.csv
echo "Date,Number" > 0to10.csv
grep "0to10" sort-age2.csv | awk '{if ($2 > 1975) {if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;}} }' | sort -n >> 0to10.csv
echo "Date,Number" > 10to20.csv
grep "10to20" sort-age2.csv | awk '{if ($2 > 1975) {if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;}} }' | sort -n >> 10to20.csv
echo "Date,Number" > 20to30.csv
grep "20to30" sort-age2.csv | awk '{if ($2 > 1975) {if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;}} }' | sort -n >> 20to30.csv
echo "Date,Number" > 30to40.csv
grep "30to40" sort-age2.csv | awk '{if ($2 > 1975) {if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;}} }' | sort -n >> 30to40.csv
echo "Date,Number" > 40to50.csv
grep "40to50" sort-age2.csv | awk '{if ($2 > 1975) {if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;}} }' | sort -n >> 40to50.csv
echo "Date,Number" > 50to60.csv
grep "50to60" sort-age2.csv | awk '{if ($2 > 1975) {if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;}} }' | sort -n >> 50to60.csv
echo "Date,Number" > 60to70.csv
grep "60to70" sort-age2.csv | awk '{if ($2 > 1975) {if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;}} }' | sort -n >> 60to70.csv
echo "Date,Number" > 70to80.csv
grep "70to80" sort-age2.csv | awk '{if ($2 > 1975) {if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;}} }' | sort -n >> 70to80.csv
echo "Date,Number" > 80to90.csv
grep "80to90" sort-age2.csv | awk '{if ($2 > 1975) {if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;}} }' | sort -n >> 80to90.csv
echo "Date,Number" > more90.csv
grep "more90" sort-age2.csv | awk '{if ($2 > 1975) {if ($4 > 9) {print $2 "-" $4 "," $1 ;} else if ($4 < 10) {print $2 "-0" $4 "," $1 ;}} }' | sort -n >> more90.csv
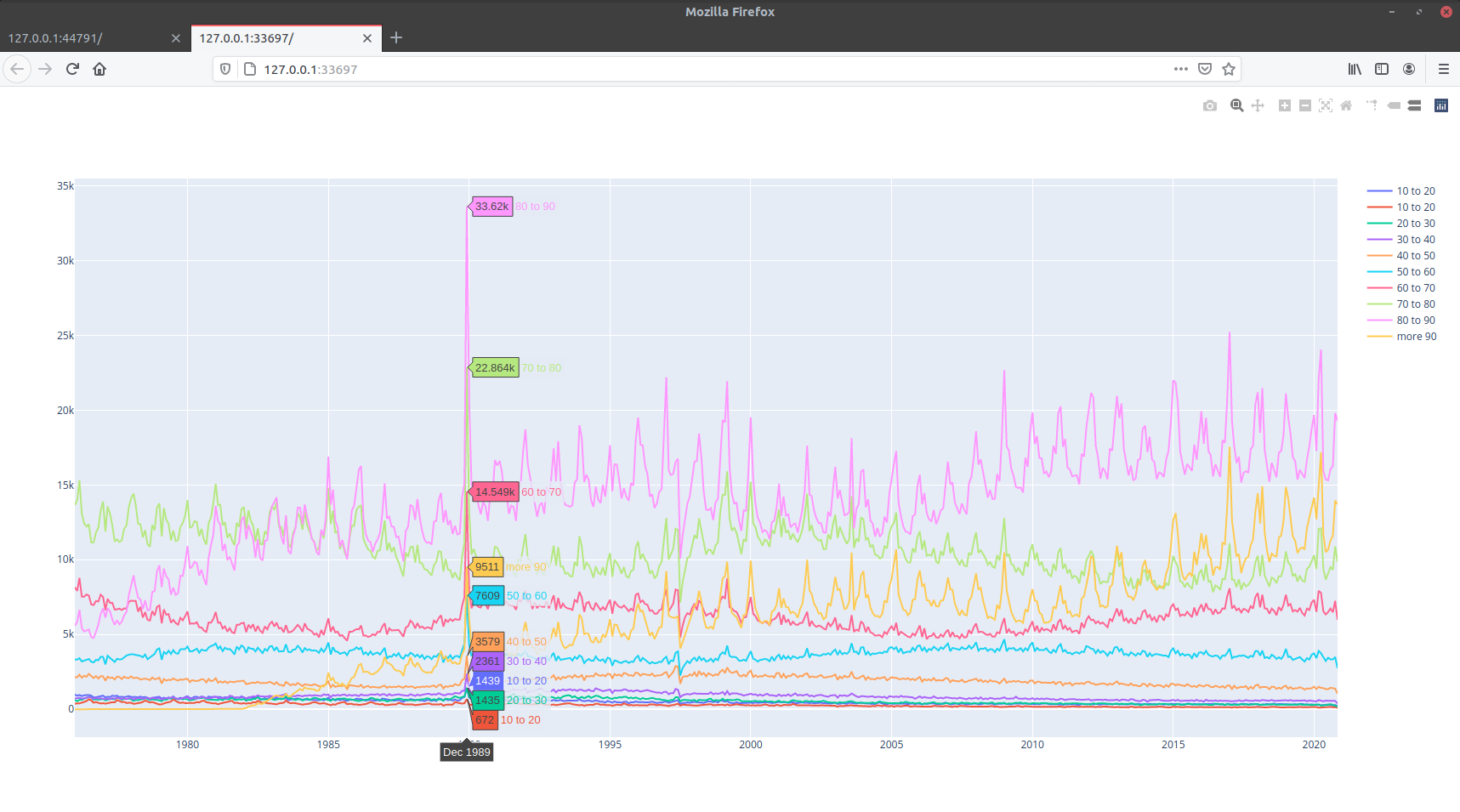
Etape 5 : Je dessine :
# cat draw2.py import plotly.graph_objects as go import pandas as pd fig = go.Figure() df = pd.read_csv('./0to10.csv') fig.add_trace(go.Scatter(x=df['Date'], y=df['Number'],name='10 to 20')) df2 = pd.read_csv('./10to20.csv') fig.add_trace(go.Scatter(x=df2['Date'], y=df2['Number'],name='10 to 20')) df3 = pd.read_csv('./20to30.csv') fig.add_trace(go.Scatter(x=df3['Date'], y=df3['Number'],name='20 to 30')) df4 = pd.read_csv('./30to40.csv') fig.add_trace(go.Scatter(x=df4['Date'], y=df4['Number'],name='30 to 40')) df5 = pd.read_csv('./40to50.csv') fig.add_trace(go.Scatter(x=df5['Date'], y=df5['Number'],name='40 to 50')) df6 = pd.read_csv('./50to60.csv') fig.add_trace(go.Scatter(x=df6['Date'], y=df6['Number'],name='50 to 60')) df7 = pd.read_csv('./60to70.csv') fig.add_trace(go.Scatter(x=df7['Date'], y=df7['Number'],name='60 to 70')) df8 = pd.read_csv('./70to80.csv') fig.add_trace(go.Scatter(x=df8['Date'], y=df8['Number'],name='70 to 80')) df9 = pd.read_csv('./80to90.csv') fig.add_trace(go.Scatter(x=df9['Date'], y=df9['Number'],name='80 to 90')) df10 = pd.read_csv('./more90.csv') fig.add_trace(go.Scatter(x=df10['Date'], y=df10['Number'],name='more 90')) fig.show() # python3 draw2.py
Le résultat, j’ai un problème sur décembre 1989 :
La suite car il y a vraiment des bons posts sur Twitter :
"Haut les mains" : un documentaire choc qui crée la polémique ! 😷 pic.twitter.com/Qd5cDW4Rca
— Bertrand Usclat (@BertrandUsclat) November 22, 2020
Pour Raphaël Enthoven, interdire le film Hold-Up est "une erreur" pic.twitter.com/85XiYbexnN
— BFMTV (@BFMTV) November 22, 2020
« Le documentaire Hold-Up pose des questions légitimes. Mais il y répond en utilisant des procédés rhétoriques manipulatoires. »#BoxeAvecLesMots : ma chronique, pour @cliquetv !pic.twitter.com/wDNryuisdm
— Clément Viktorovitch (@clemovitch) November 22, 2020
https://t.co/ciOKxHNt8z pic.twitter.com/q44zTO4iXq
— Raphael Grably (@GrablyR) November 22, 2020
HOLD Up le Film : la vérité c’est important !
Très bon article de @Acermendax https://t.co/VKXwQTyd5C
— Laure Dasinieres (@LUppsala) November 21, 2020
Artisan de la promotion du documentaire complotiste "Hold-Up", le site internet FranceSoir a gagné une nouvelle notoriété depuis le début de la pandémie, surfant sur le titre prestigieux de son ancêtre de papier https://t.co/EpJuXG1PmB #AFP 1/12 ⤵️ pic.twitter.com/JCJVVh1ZOg
— Agence France-Presse (@afpfr) November 21, 2020
Si vous avez vu #holdup_ledoc vous vous posez sûrement cette question : Qui a bien pu faire ce film ? Car c'est un doc à gros budget (300000 euros). Professionnel sur l'image, le montage, la narration. Portrait du réalisateur Pierre Barnérias par @Marion_Mercier pour #VraiOuFake pic.twitter.com/geFar3mMzs
— Julien Pain (@JulienPain) November 20, 2020
Les scientifiques apparaissant dans Hold-Up sont-ils complotistes ? Bonne question, voyons cela. https://t.co/RaW5gQwGIg
— VFP le scintigraphiste (@Scintigraphiste) November 19, 2020
Lauréat du "Rasoir Rouillé" 2020 récompensant la pire contribution en faveur des pseudosciences : @raoult_didier
Les sceptiques britanniques et les sceptiques français arrivent à une sorte de… consensus. https://t.co/BCKpWSkzmF
— Acermendax (@Acermendax) November 20, 2020
La vérité, c'est important !
C'est pourquoi l'histoire que nous raconte le film #HoldUp provoque un tel retentissement : ce qu'on y entend est grave !Et si nous examinions tout ça en nous posant de bonnes questions ?
Pensez à partager 😉https://t.co/YbVraOIuB3
— La Tronche en Biais (@TroncheBiais) November 20, 2020
Qui est Olivier Vuillemin, le Suisse présenté comme expert scientifique dans Hold-Up? | via @heidi_news https://t.co/wjU4tNRD9m
— Sarah Sermondadaz (@datisdaz) November 20, 2020
Avec le Covid-19, le site FranceSoir, repris par Xavier Azalbert en 2016, gagne une nouvelle notoriété dans le sillage d’un traitement de l’information à la lisière permanente du #complotisme.https://t.co/VoY8W8SrlB
— Conspiracy Watch (@conspiration) November 20, 2020
https://twitter.com/WTFake_/status/1329507617127981056?s=20
Parce que je démonte #holdup_ledoc certains me disent "pourquoi tu n'acceptes pas qu'on pense différemment?". Je ne travaille pas sur des opinions. Avec l'équipe, on essaie de donner à tous des faits vérifiés pour qu'ensuite chacun puisse se forger une opinion. THREAD #VraiOuFake
— Julien Pain (@JulienPain) November 20, 2020
Je fais donc la liste des comptes à suivre et à bloquer pour un ami … ensuite il faut ajouter à cette liste quelques médias tels que franceinfo , Le Monde, Libération, France Inter, Agence France Presse, France Culture. Liste des comptes à suivre :
C’est une liste de 30 sur mes 410 abonnements … l’ideal est de suivre moins de 500 comptes sinon ce n’est pas vraiment possible.
Liste des comptes à bloquer :
Statistique de @CYBERNEURONES :
| Tweets | Impressions du Tweet | Visites du profil | Mentions | Nouveaux abonnés | |
| aout 20 | 76 | 36000 | 236 | 74 | 9 |
| juillet 20 | 41 | 18000 | 98 | 47 | -1 |
| juin 20 | 109 | 35200 | 217 | 78 | 2 |
| mai 20 | 256 | 100000 | 655 | 127 | 10 |
| avril 20 | 234 | 74700 | 438 | 107 | 3 |
| mars 20 | 85 | 42500 | 317 | 21 | 4 |
| février 20 | 144 | 19900 | 349 | 25 | 8 |
| janvier 20 | 140 | 44300 | 378 | 74 | 10 |
| décembre 19 | 82 | 41900 | 213 | 18 | 2 |
| novembre 19 | 89 | 24600 | 152 | 86 | 6 |
| octobre 19 | 25 | 8256 | 50 | 10 | 8 |
| aout 19 | 49 | 15200 | 168 | 11 | -3 |
| juillet 19 | 40 | 9292 | 111 | 4 | 4 |
| juin 19 | 53 | 11700 | 191 | 37 | -1 |
| mai 19 | 96 | 24600 | 313 | 9 | 12 |
| avril 19 | 38 | 11300 | 154 | 10 | 3 |
| mars 19 | 79 | 30000 | 262 | 16 | 3 |
| février 19 | 2 | 32900 | 10 | 1 | 1 |
| janv 19 | – | 84800 | – | – | 5 |
| déc. 18 | 161 | 111000 | 521 | 65 | 11 |
| nov. 18 | 54 | 20300 | 253 | 23 | 5 |
| oct. 18 | 52 | 33000 | 184 | 16 | 2 |
| sept. 18 | 58 | 19800 | 173 | 8 | 2 |
| août 18 | 22 | 12000 | 55 | 6 | 2 |
| juil. 18 | 30 | 19800 | 87 | 5 | -12 |
| juin 18 | 74 | 25100 | 166 | 37 | 14 |
| mai 18 | 59 | 14800 | 121 | 15 | 2 |
| avr. 18 | 63 | 34900 | 148 | 7 | 1 |
| mars 18 | 133 | 55500 | 220 | 31 | 15 |
| févr. 18 | 68 | 24500 | 163 | 12 | 5 |
| janv. 18 | 91 | 27700 | 212 | 18 | 3 |
| déc. 17 | 63 | 16100 | 292 | 15 | -1 |
| nov. 17 | 77 | 22900 | 152 | 30 | 0 |
| oct. 17 | 90 | 30400 | 200 | 55 | 6 |
| sept. 17 | 96 | 32400 | 262 | 20 | -2 |
| août 17 | 106 | 23700 | 260 | 41 | 7 |
| juil. 17 | 89 | 28600 | 135 | 16 | 1 |