J’ai trouvé un outil de test de llm : llm_benchmark ( installation via pip )
- https://pypi.org/project/llm-benchmark/
- https://github.com/aidatatools/ollama-benchmark
- https://llm.aidatatools.com/
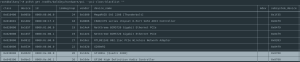
Je suis en dernière position : https://llm.aidatatools.com/results-linux.php , avec « llama3.1:8b »: « 1.12 ».

![]()
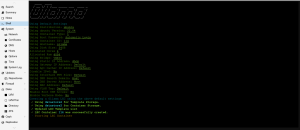
llm_benchmark run
-------Linux----------
{'id': '0', 'name': 'Quadro 4000', 'driver': '390.157', 'gpu_memory_total': '1985.0 MB',
'gpu_memory_free': '1984.0 MB', 'gpu_memory_used': '1.0 MB', 'gpu_load': '0.0%',
'gpu_temperature': '60.0°C'}
Only one GPU card
Total memory size : 61.36 GB
cpu_info: Intel(R) Xeon(R) CPU E5-2450 v2 @ 2.50GHz
gpu_info: Quadro 4000
os_version: Ubuntu 22.04.5 LTS
ollama_version: 0.5.7
----------
LLM models file path:/usr/local/lib/python3.10/dist-packages/llm_benchmark/data/benchmark_models_16gb_ram.yml
Checking and pulling the following LLM models
phi4:14b
qwen2:7b
gemma2:9b
mistral:7b
llama3.1:8b
llava:7b
llava:13b
----------
model_name = mistral:7b
prompt = Write a step-by-step guide on how to bake a chocolate cake from scratch.
eval rate: 1.51 tokens/s
prompt = Develop a python function that solves the following problem, sudoku game
eval rate: 1.30 tokens/s
prompt = Create a dialogue between two characters that discusses economic crisis
eval rate: 1.52 tokens/s
prompt = In a forest, there are brave lions living there. Please continue the story.
eval rate: 1.44 tokens/s
prompt = I'd like to book a flight for 4 to Seattle in U.S.
eval rate: 1.25 tokens/s
--------------------
Average of eval rate: 1.404 tokens/s
----------------------------------------
model_name = llama3.1:8b
prompt = Write a step-by-step guide on how to bake a chocolate cake from scratch.
eval rate: 1.19 tokens/s
prompt = Develop a python function that solves the following problem, sudoku game
eval rate: 1.20 tokens/s
prompt = Create a dialogue between two characters that discusses economic crisis
eval rate: 1.02 tokens/s
prompt = In a forest, there are brave lions living there. Please continue the story.
eval rate: 1.22 tokens/s
prompt = I'd like to book a flight for 4 to Seattle in U.S.
eval rate: 0.95 tokens/s
--------------------
Average of eval rate: 1.116 tokens/s
----------------------------------------
model_name = phi4:14b
prompt = Write a step-by-step guide on how to bake a chocolate cake from scratch.
eval rate: 0.76 tokens/s
prompt = Develop a python function that solves the following problem, sudoku game
eval rate: 0.76 tokens/s
prompt = Create a dialogue between two characters that discusses economic crisis
eval rate: 0.76 tokens/s
prompt = In a forest, there are brave lions living there. Please continue the story.
eval rate: 0.72 tokens/s
prompt = I'd like to book a flight for 4 to Seattle in U.S.
eval rate: 0.80 tokens/s
--------------------
Average of eval rate: 0.76 tokens/s
----------------------------------------
model_name = qwen2:7b
prompt = Write a step-by-step guide on how to bake a chocolate cake from scratch.
eval rate: 1.41 tokens/s
prompt = Develop a python function that solves the following problem, sudoku game
eval rate: 1.38 tokens/s
prompt = Create a dialogue between two characters that discusses economic crisis
eval rate: 1.31 tokens/s
prompt = In a forest, there are brave lions living there. Please continue the story.
eval rate: 1.18 tokens/s
prompt = I'd like to book a flight for 4 to Seattle in U.S.
eval rate: 1.29 tokens/s
--------------------
Average of eval rate: 1.314 tokens/s
----------------------------------------
model_name = gemma2:9b
prompt = Explain Artificial Intelligence and give its applications.
eval rate: 1.01 tokens/s
prompt = How are machine learning and AI related?
eval rate: 1.40 tokens/s
prompt = What is Deep Learning based on?
eval rate: 0.89 tokens/s
prompt = What is the full form of LSTM?
eval rate: 0.86 tokens/s
prompt = What are different components of GAN?
eval rate: 1.00 tokens/s
--------------------
Average of eval rate: 1.032 tokens/s
----------------------------------------
model_name = llava:7b
prompt = Describe the image, /usr/local/lib/python3.10/dist-packages/llm_benchmark/data/img/sample1.jpg
eval rate: 0.86 tokens/s
prompt = Describe the image, /usr/local/lib/python3.10/dist-packages/llm_benchmark/data/img/sample2.jpg
eval rate: 2.44 tokens/s
prompt = Describe the image, /usr/local/lib/python3.10/dist-packages/llm_benchmark/data/img/sample3.jpg
eval rate: 1.53 tokens/s
prompt = Describe the image, /usr/local/lib/python3.10/dist-packages/llm_benchmark/data/img/sample4.jpg
eval rate: 1.80 tokens/s
prompt = Describe the image, /usr/local/lib/python3.10/dist-packages/llm_benchmark/data/img/sample5.jpg
eval rate: 2.56 tokens/s
--------------------
Average of eval rate: 1.838 tokens/s
----------------------------------------
model_name = llava:13b
prompt = Describe the image, /usr/local/lib/python3.10/dist-packages/llm_benchmark/data/img/sample1.jpg
eval rate: 0.67 tokens/s
prompt = Describe the image, /usr/local/lib/python3.10/dist-packages/llm_benchmark/data/img/sample2.jpg
eval rate: 0.67 tokens/s
prompt = Describe the image, /usr/local/lib/python3.10/dist-packages/llm_benchmark/data/img/sample3.jpg
eval rate: 0.77 tokens/s
prompt = Describe the image, /usr/local/lib/python3.10/dist-packages/llm_benchmark/data/img/sample4.jpg
eval rate: 1.10 tokens/s
prompt = Describe the image, /usr/local/lib/python3.10/dist-packages/llm_benchmark/data/img/sample5.jpg
eval rate: 0.45 tokens/s
--------------------
Average of eval rate: 0.732 tokens/s
----------------------------------------
Sending the following data to a remote server
-------Linux----------
{'id': '0', 'name': 'Quadro 4000', 'driver': '390.157', 'gpu_memory_total': '1985.0 MB',
'gpu_memory_free': '1984.0 MB', 'gpu_memory_used': '1.0 MB', 'gpu_load': '0.0%',
'gpu_temperature': '61.0°C'}
Only one GPU card
-------Linux----------
{'id': '0', 'name': 'Quadro 4000', 'driver': '390.157', 'gpu_memory_total': '1985.0 MB',
'gpu_memory_free': '1984.0 MB', 'gpu_memory_used': '1.0 MB', 'gpu_load': '0.0%',
'gpu_temperature': '61.0°C'}
Only one GPU card
{
"mistral:7b": "1.40",
"llama3.1:8b": "1.12",
"phi4:14b": "0.76",
"qwen2:7b": "1.31",
"gemma2:9b": "1.03",
"llava:7b": "1.84",
"llava:13b": "0.73",
"uuid": "",
"ollama_version": "0.5.7"
}
----------