
Enfin des données en ligne pour des analyses statistiques : https://www.data.gouv.fr/fr/ . A lire l’article : http://www.lefigaro.fr/secteur/high-tech/2016/01/12/32001-20160112ARTFIG00389-le-gouvernement-accelere-l-ouverture-des-donnees-publiques.php : Le gouvernement accélère l’ouverture des données publiques .
Les premières données que j’ai voulu prendre concerne: Réserve parlementaire . J’ai voulu m’abonner a ce jeu de données :

Il faut ouvrir un compte, j’ai opté pour la création d’un compte via Google, mais ce fut un premier échec :
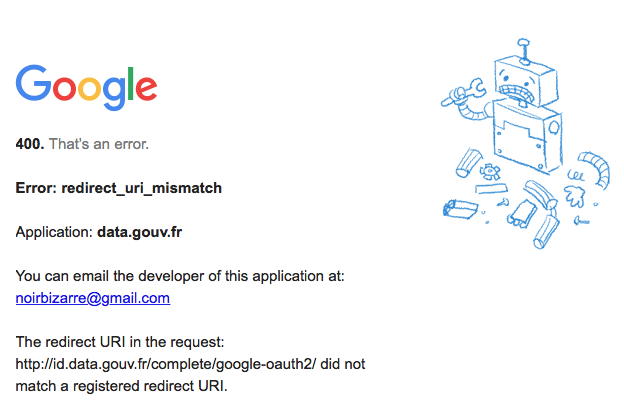
Ensuite j’ai essayé le suivant, encore un problème linckedin :
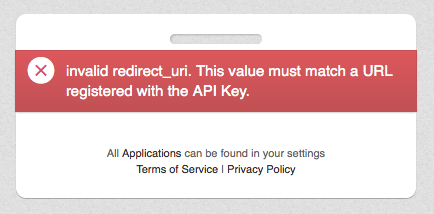
Et pour finir twitter, pareil … je n’ai pas vu Facebook. C’est pourtant le plus gros réseaux, mais bon c’est sur que pour les professionnels c’est pas l’idéal. Finalement j’ai fait une inscription à la main … et maintenant je peux suivre ses données :

La validation du site a du être faite rapidement … on va dire que ce sont des erreurs de débutant.
On revient donc à nos moutons, pour les personnes qui ne connaissent pas les réserves parlementaires voici un lien :
http://www.assemblee-nationale.fr/budget/reserve_parlementaire.asp
Un député a la possibilité de proposer l’attribution de subventions à hauteur de 130 000 euros en moyenne, la modulation de la répartition entre les députés relevant de chaque groupe politique. Les membres du Bureau de l’Assemblée nationale disposent d’une réserve de 140 000 euros, les vice-présidents de l’Assemblée nationale, les questeurs, les présidents de groupe, les présidents de commission disposent de 260 000 euros, le Président de l’Assemblée nationale de 520 000 euros. Le montant de la réserve institutionnelle de l’Assemblée nationale a été fixé en 2014 à 5,5 millions d’euros.
Sinon si vous voulez une version plus proche de la vérité, Wikipedia c’est pas mal : https://fr.wikipedia.org/wiki/Réserve_parlementaire
Certains journalistes dénoncent l’attribution de subventions provenant de la réserve parlementaire à des associations servant directement ou indirectement les intérêts des parlementaires qui les attribuent. Le député François Grosdidier est mis en cause pour avoir financé une association proche de ses intérêts.
Le sénateur Philippe Marini est critiqué en 2013 pour des financements de 340 750 € d’un centre équestre dont une association présidée par son épouse est une utilisatrice importante.
Maintenant on s’occupe des fichiers, on n’est pas là pour faire de la politique.
La version CSV , mais le mieux est d’oublier cette version:
100% sport et loisirs,,Fonctionnement,1000.00,CINIERI,Dino,Loire,UMP,219-01,PA267429
La version JSON :
{ "Bénéficiaire":"Télé Bocal", "Adresse":"Maison des associations\n1/3 rue Frédérique Lemaître\n75020 Paris", "Descriptif":"Mise en œuvre d'ateliers de production locale proposant d’utiliser l'image comme une valorisation du travail des artistes", "Montant":5000, "Nom":"BAUPIN", "Prénom":"Denis", "Département":"Paris", "Groupe":"Ecolo", "Programme budgétaire":"313-03", "ID_Acteur":"PA609016" },
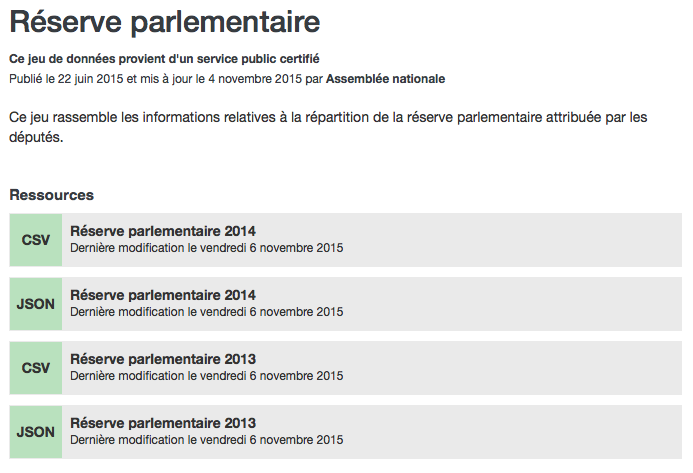
C’est dommage il n’y a que 2013 & 2014. Maintenant il ne reste plus qu’à faire une analyse de ses dons.
Quelques commandes Linux pour se chauffer, j’opte pour le format JSON car le CSV va avoir des problèmes avec les retours chariots :
- Connaitre les 5 plus gros montants en 2013
$ grep "Montant" 2013_reserve_parlementaire.json | awk '{print $3}' | sed 's/,/ /g' | sort -n | uniq -c | tail -5
4 110000.00
1 120000.00
7 130000.00
1 140000.00
2 150000.00
2 160000.00
1 170000.00
1 195000.00
4 200000.00
2 250000.00
Il y a donc eu deux montant de 250.000 Euros en 2013.
- Connaitre les 10 montants les plus communs en 2013
$ grep "Montant" 2013_reserve_parlementaire.json | awk '{print $3}' | sed 's/,/ /g' | sort -n | uniq -c | sort -n | tail -10
276 2500.00
335 20000.00
363 15000.00
469 4000.00
508 1500.00
756 3000.00
962 2000.00
1069 10000.00
1124 5000.00
2350 1000.00
La majorité des montants sont de 1000 Euro. Ce qui est plus que symbolique … Petite explication pour ceux qui ne le savent pas :
- Gauche Démocrate et Républicaine (GDR)
- Socialiste, Républicain et Citoyen (SRC)
- Écologiste (ECOLO)
- Radical, Républicain, Démocrate et Progressiste (RRDP)
- Union des Démocrates et Indépendants (UDI)
- Les Républicains (LES-REP)
- Députés Non Inscrits (NI)
- UMP (UMP)
- … (NULL) … je ne sais pas qui se cache derrière cela, je sais seulement qu’il a donné 3000 Euros au « Club des plus belles baies du monde« . Cela doit être UMP 😉
- Connaitre les 10 plus gros montants en 2014
$ grep "Montant" 2014_reserve_parlementaire.json | sed 's/:/ /g' | awk '{print $2}' | sed 's/,/ /g' | sort -n | uniq -c | sort -n | tail -10
290 20000
318 15000
358 2500
601 4000
697 1500
1033 10000
1116 3000
1397 5000
1455 2000
3065 1000
- Connaitre les 5 départements les plus cités en 2013
$ grep "tement' " 2013_reserve_parlementaire.json | awk '{print $2 " " $3 " " $4}' | sed 's/,/ /g' | sort -n | uniq -c | sort -n | tail -5
308 : 'Alpes-Maritimes'
312 : 'Bouches-du-Rhône'
325 : 'Paris'
410 : 'Rhône'
447 : 'Nord'
Bonne position pour les Alpes-Maritimes.
- Connaitre les 5 départements les moins cités en 2013
$ grep "tement' " 2013_reserve_parlementaire.json | awk '{print $2 " " $3 " " $4}' | sed 's/,/ /g' | sort -n | uniq -c | sort -n | head -5
5 : 'Saint-Pierre-et-Miquelon'
10 : 'Mayotte'
11 : 'Wallis-et-Futuna'
14 : 'Ariège'
15 : 'Guyane'
L’Ariège … l’autre DOM-TOM 😉
- Connaitre le nombre de dons par groupe en 2014
$ grep 'Groupe":' 2014_reserve_parlementaire.json | sed 's/:/ /g' | awk '{print $2 " " $3 " " $4}' | sed 's/,/ /g' | sort -n | uniq -c
52 ""
549 "Ecolo"
148 "GDR"
128 "NI"
262 "RRDP"
5172 "SRC"
741 "UDI"
6081 "UMP"
- Connaitre le nombre de dons par groupe en 2013
$ grep "Groupe' " 2013_reserve_parlementaire.json | awk '{print $2 " " $3 " " $4}' | sed 's/,/ /g' | sort -n | uniq -c
288 : ''
416 : 'ECOLO'
98 : 'GDR'
66 : 'NI'
1 : 'RGB'
229 : 'RRDP'
3 : 'SRC '
3727 : 'SRC'
583 : 'UDI'
5544 : 'UMP'
1 : NULL
Le partie NULL … enfin un qui apparait sous sa vrai couleur 🙂
- Connaitre les mots qui reviennent le plus dans les bénéficiaires en 2013
$ grep "ciaire' : '" 2013_reserve_parlementaire.json | awk -F"'" '{print $4}' | awk '{for (i=1;i<20;i++) {if (length($i) > 2) mots[tolower($i)]++;}} END {for (x in mots) {printf mots[x] " " x "\n"}}' | sort -n | tail -30
53 france
54 culture
56 parents
57 française
62 rugby
63 pays
69 société
71 maison
71 syndicat
73 tennis
78 loisirs
85 ecole
86 fêtes
93 football
101 communauté
102 communes
104 centre
116 union
124 pour
125 amicale
159 amis
174 comité
178 sur
195 sportive
318 saint
485 club
499 les
843 des
1044 association
4456 commune
On peut faire un classement des sports : 1-football ou foot / 2-tennis / 3-rugby / 4-basket / 5-judo / 6-handball / 7-pétanque ou boule / 8-ski / 9-gymnastique ou gym / 10-volley …
On trouve aussi les synonymes de notre chère laïcité, comme par exemple : catholique, … 🙂
- Connaitre les mots qui reviennent le plus dans le descriptif en 2013
$ grep "ptif' : '" 2013_reserve_parlementaire.json | awk -F"'" '{print $4}' | awk '{for (i=1;i<20;i++) {if (length($i) > 2) mots[tolower($i)]++;}} END {for (x in mots) {printf mots[x] " " x "\n"}}' | sort -n | tail -10
296 pour
321 création
331 construction
359 achat
378 réfection
384 rénovation
592 aménagement
847 des
1099 travaux
4206 fonctionnement
Beaucoup de synonymes : réfection, rénovation, réhabilitation, restauration ….
Toujours plus fort dans notre cours de awk …
- Connaitre le montant moyen en fonction du groupe en 2013
$ cat 2014_reserve_parlementaire.json | awk -F":" '{if ($1 ~ "Groupe") {Groupe[$2]+=montant; Nombre[$2]++}; if ($1 ~ "Montant") {montant=$2}} END {for (x in Groupe) {print x " " Groupe[x] " " Nombre [x] " " eval (Groupe[x]/Nombre[x]) "\n" }}'
"GDR", 2101366 148 14198.4
"", 2856000 52 54923.1
"Ecolo", 2637890 549 4804.9
"SRC", 40323770 5172 7796.55
"RRDP", 2309018 262 8813.05
"UMP", 24608557 6081 4046.79
"NI", 1142574 128 8926.36
"UDI", 4092383 741 5522.78
Et si l’on veut soigner la présentation :
- Connaitre le montant moyen en fonction du groupe en 2014
cat 2013_reserve_parlementaire.json | awk -F":" 'BEGIN {print "Groupe \tTotal \tNombre\tMoyenne"} {if ($1 ~ "Groupe") {Groupe[$2]+=montant; Nombre[$2]++}; if ($1 ~ "Montant") {montant=$2}} END {for (x in Groupe) {print x " \t" Groupe[x] " \t" Nombre [x] "\t" eval (Groupe[x]/Nombre[x]) "\n" }}'
Groupe Total Nombre Moyenne
'GDR', 1839172 98 18767.1
'SRC ', 13500 3 4500
'UDI', 3847987 583 6600.32
'RGB', 3000 1 3000
'ECOLO', 2131500 416 5123.8
NULL, 3000 1 3000
'UMP', 24982561 5544 4506.23
'SRC', 3.9262e+07 3727 10534.5
'NI', 891300 66 13504.5
'', 6440315 288 22362.2
'RRDP', 2100475 229 9172.38
Maintenant on peut faire le même calcul en fonction du nom et en plus connaitre le min et le max pour chacun.
- Connaitre le montant moyen, le min et le max en fonction du nom en 2013
$ cat 2013_reserve_parlementaire.json | awk -F":" 'BEGIN {print "Groupe \tTotal \tNombre\tMoyenne\tMin\tMax"} {if ($1 ~ "Nom") {nom = tolower($2); gsub(" ","_", nom); Groupe[nom]+=montant; Nombre[nom]++; if (Nombre[nom] == 1) min[nom] = montant; if (montant > max[nom]) max[nom] = montant; if (montant < min[nom]) min[nom] = montant}; if ($1 ~ "Montant") {montant=$2}} END {for (x in Groupe) {print x " \t" Groupe[x] " \t" Nombre [x] "\t" eval (Groupe[x]/Nombre[x]) "\t" min [x] "\t" max [x] "\n" }}' | sort -nk2 | tail -20
_'briand', 254500 23 11065.2 1000.00, 7500.00,
_'dumas', 258534 26 9943.62 10000.00, 6000.00,
_'faure', 259300 24 10804.2 10000.00, 9300.00,
_'bachelay', 260000 18 14444.4 1000.00, 5000.00,
_'chanteguet', 260000 18 14444.4 10000.00, 9500.00,
_'eckert', 260000 30 8666.67 10000.00, 50000.00,
_'le_roux_', 260000 5 52000 10000.00, 70000.00,
_'le_fur', 260200 25 10408 1000.00, 6500.00,
_'vautrin', 262400 19 13810.5 10000.00, 7000.00,
_'geoffroy', 270000 18 15000 1000.00, 8000.00,
_'marleix', 278400 45 6186.67 1000.00, 8000.00,
_'gosselin', 280750 69 4068.84 1000.00, 850.00,
_'chassaigne', 286500 35 8185.71 10000.00, 8000.00,
_'groupe_ecolo', 309500 29 10672.4 10000.00, 9000.00,
_'dumont', 362550 57 6360.53 10000.00, 9000.00,
_'vigier', 381830 85 4492.12 1000.00, 9000.00,
_'bartolone', 520000 7 74285.7 195000.00, 6000.00,
_'carrez', 786500 43 18290.7 1000.00, 8000.00,
_'groupe_src', 2465334 180 13696.3 1000.00, 9309.00,
_'Présidence_de_l\'assemblée_nationale', 3117000 49 63612.2 1000.00, 90000.00,
- Connaitre le montant moyen en 2013
cat 2013_reserve_parlementaire.json | awk -F":" '{if ($1 ~ "Nom") {nom = tolower($2); gsub(" ","_", nom); Groupe[nom]+=montant; Nombre[nom]++; if (Nombre[nom] == 1) min[nom] = montant; if (montant > max[nom]) max[nom] = montant; if (montant < min[nom]) min[nom] = montant}; if ($1 ~ "Montant") {montant=$2}} END {for (x in Groupe) {print x " \t" Groupe[x] " \t" Nombre [x] "\t" eval (Groupe[x]/Nombre[x]) "\t" min [x] "\t" max [x] "\n" }}' | sort -nk2 | awk '{print $2}' | sort -n | uniq -c | sort -n | tail -5
10 125000
11 117000
26 110000
219 130000
On retrouve les 130.000 Euro …
- Connaitre le nombre don fait pour les personnes ayant mis 130.000 Euro en 2013
$ cat 2013_reserve_parlementaire.json | awk -F":" '{if ($1 ~ "Nom") {nom = tolower($2); gsub(" ","_", nom); Groupe[nom]+=montant; Nombre[nom]++; if (Nombre[nom] == 1) min[nom] = montant; if (montant > max[nom]) max[nom] = montant; if (montant < min[nom]) min[nom] = montant}; if ($1 ~ "Montant") {montant=$2}} END {for (x in Groupe) {if (Groupe[x] == 130000) {print x " \t" Groupe[x] " \t" Nombre [x] "\t" eval (Groupe[x]/Nombre[x]) "\t" min [x] "\t" max [x] "\n"} }}' | sort -nk 3
[…]
_'bello', 130000 1 130000 130000.00, 130000.00,
_'dufour-tonini', 130000 1 130000 130000.00, 130000.00,
_'franÇaix', 130000 1 130000 130000.00, 130000.00,
_'rouquet', 130000 1 130000 130000.00, 130000.00,
_'le_bouillonnec', 130000 2 65000 100000.00, 30000.00,
_'raimbourg', 130000 2 65000 10000.00, 120000.00,
_'gagnaire', 130000 3 43333.3 10000.00, 17000.00,
[…]
_'richard_arnaud_', 130000 51 2549.02 1000.00, 7500.00,
_'drapeau', 130000 52 2500 1000.00, 8000.00,
_'battistel', 130000 54 2407.41 1000.00, 9500.00,
_'chambefort', 130000 54 2407.41 1500.00, 3500.00,
_'aubert', 130000 65 2000 1000.00, 6000.00,
_'lamour', 130000 67 1940.3 1500.00, 6000.00,
_'salles_rudy_', 130000 81 1604.94 1000.00, 6000.00,
[…]
Il y a deux stratégies, ceux qui arrosent larges (comme Salles rudy avec 81) et ceux qui ne font qu’un seul don.
Dans les précédentes commandes le min & le max ne fonctionnaient pas, car j’ai fait l’erreur commune de me servir de > à la place de faire -. J’ai donc un travail sur les chaines de caractères (string) à la place d’avoir un travail sur le contenu. Vous aviez vu l’erreur ?
Alors je vous mets un dernier avec la correction.
- Connaitre le montant moyen, le min et le max en fonction du département en 2013
$ cat 2013_reserve_parlementaire.json | awk -M -F":" '{if ($1 ~ /partement/) {nom = tolower($2); gsub(" ","_", nom); gsub (",","",montant); Groupe[nom]+=montant; Nombre[nom]++; if (Nombre[nom] == 1) min[nom] = montant; if ((montant - max[nom]) > 0) max[nom] = montant; if ((montant - min[nom]) < 0) min[nom] = montant}; if ($1 ~ "Montant") {montant=$2}} END {for (x in Groupe) { {print x " \t" Groupe[x] " \t" Nombre [x] "\t" eval (Groupe[x]/Nombre[x]) "\t" min [x] "\t" max [x] "\n"} }}' | sort -nk 2
[…]
_'pas-de-calais', 1.51015e+06 199 7588.68 1000.00 40249.45
_'creuse', 130700 19 6878.95 1800.00 25000.00
_'lozère', 133973 55 2435.87 1000.00 10000.00
[…]
_'oise', 938325 268 3501.21 550.00 130000.00
_'alpes-maritimes', 957541 308 3108.9 1000.00 140000.00
_'ille-et-vilaine', 1043710 75 13916.1 1000.00 63000.00
_'bas-rhin', 1088584 205 5310.17 1000.00 50000.00
_'hérault', 1108630 113 9810.88 1000.00 40000.00
_'moselle', 1165285 235 4958.66 771.00 43000.00
_'finistère', 1189900 83 14336.1 1000.00 59000.00
_'essonne', 1238975 122 10155.5 1000.00 55000.00
_'seine-maritime', 1251592 133 9410.47 500.00 55000.00
_'val-d\'oise', 1271484 160 7946.77 350.00 130000.00
_'haute-garonne', 1312250 142 9241.2 1000.00 104000.00
_'loire-atlantique', 1324200 146 9069.86 1000.00 120000.00
_'français_établis_hors_de_france', 1339930 156 8589.29 1000.00 50000.00
_'hauts-de-seine', 1358000 60 22633.3 1500.00 110000.00
_'isère', 1368500 231 5924.24 1000.00 130000.00
_'gironde', 1407458 150 9383.05 1000.00 77500.00
_'yvelines', 1446835 267 5418.86 1000.00 94000.00
_'seine-et-marne', 1518028 197 7705.73 1000.00 100000.00
_'rhône', 1801338 410 4393.51 500.00 62500.00
_'bouches-du-rhône', 1975877 312 6332.94 500.00 66000.00
_'val-de-marne', 2030500 151 13447 1000.00 200000.00
_'seine-saint-denis', 2115500 91 23247.3 2000.00 200000.00
_'paris', 2281000 325 7018.46 1000.00 70000.00
_'nord', 2699364 447 6038.85 594.00 130000.00
_'*(non_rattaché_un_département)', 6183315 284 21772.2 600.00 250000.00
Sur ce dernier on peut voir l’échec de la fonction -M qui ne devrait pas m’afficher un exposant pour le Pas de Calais. Ou alors j’ai mal compris 😉 .
En fait pour que cette option fonctionne il faut faire un printf, par exemple :
$ cat 2013_reserve_parlementaire.json | awk -M -F":" '{if ($1 ~ /partement/) {nom = tolower($2); gsub(" ","_", nom); gsub (",","",montant); Groupe[nom]+=montant; Nombre[nom]++; if (Nombre[nom] == 1) min[nom] = montant; if ((montant - max[nom]) > 0) max[nom] = montant; if ((montant - min[nom]) < 0) min[nom] = montant; total += montant}; if ($1 ~ "Montant") {montant=$2}} END {for (x in Groupe) { {printf ("%40s\t%ld\t%ld\t%ld\t%ld\t%ld\n",x,Groupe[x],Nombre[x],(Groupe[x]/Nombre[x]),min[x],max[x])}} printf ("Total : \t\t\t\t%ld",total)}' | tail -10
_'doubs', 634898 121 5247 1000 20000
_'var', 874487 146 5989 1000 110000
_'aisne', 631095 113 5584 1000 50000
_'côte-d\'or', 648822 80 8110 1000 67000
_'orne', 400700 61 6568 400 20000
_'bas-rhin', 1088584 205 5310 1000 50000
_'drôme', 629355 71 8864 1000 70000
_'sarthe', 652950 58 11257 1500 50000
_'haute-loire', 282500 65 4346 1000 37000
Total : 81514813
$ cat 2014_reserve_parlementaire.json | awk -M -F":" '{if ($1 ~ /partement/) {nom = tolower($2); gsub(" ","_", nom); gsub (",","",montant); Groupe[nom]+=montant; Nombre[nom]++; if (Nombre[nom] == 1) min[nom] = montant; if ((montant - max[nom]) > 0) max[nom] = montant; if ((montant - min[nom]) < 0) min[nom] = montant; total += montant}; if ($1 ~ "Montant") {montant=$2}} END {for (x in Groupe) { {printf ("%40s\t%ld\t%ld\t%ld\t%ld\t%ld\n",x,Groupe[x],Nombre[x],(Groupe[x]/Nombre[x]),min[x],max[x])}} printf ("Total : \t\t\t\t%ld",total)}' | tail -10
"vienne", 506996 62 8177 1000 30000
"indre", 388000 45 8622 1000 77000
"haute-corse", 279415 43 6498 1650 35000
"cantal", 268000 61 4393 1000 15000
"hauts-de-seine", 1372261 112 12252 1000 110000
"tarn", 392133 78 5027 1000 20000
"pyrénées-atlantiques", 779800 83 9395 1000 49000
"allier", 394000 71 5549 1000 30000
"charente", 390000 43 9069 1000 108500
Total : 80071558
J’arrête donc de jouer avec l’argent pour aujourd’hui.
Conclusion :
Mieux que Excel : cat & awk & sed & sort & tail & uniq . Simple & convivial 😉
Les fichiers JSON sont mal faits, et je ne parle pas du fichier CSV. Mais ils sont certifiées … à mon avis, certifiées par un stagiaire en informatique.
0-Les fichiers CSV sont très mal fait, d’abord il est complètement stupide de pendre la virgule (« , ») et non le point-virgule (« ; ») comme séparateur. Forcément on va trouver des virgules dans les textes ?!
Donc un monde idéal je devrais toujours avoir le même nombre de virgule par ligne, à savoir 9 :
$ cat 2013_reserve_parlementaire.csv | awk -F "," '{print NF-1 }' | sort -n | uniq -c
9 -1
680 0
1958 1
479 2
24 3
8 4
76 7
1898 8
8300 9
505 10
115 11
41 12
15 13
6 14
1 15
$ cat 2014_reserve_parlementaire.csv | awk -F "," '{print NF-1 }' | sort -n | uniq -c
348 0
817 1
268 2
25 3
4 4
1 5
1 6
75 7
844 8
10496 9
1299 10
313 11
80 12
16 13
8 14
2 15
1 17
1 20
Ensuite si on injecte cela dans Excel cela ne va rien donner de bon ?!
Si on avait choisi le « ; » on n’aurait eu quasiment aucun problème :
$ cat 2014_reserve_parlementaire.csv | awk -F ";" '{print NF-1 }' | sort -n | uniq -c
14588 0
10 1
1 2
$ cat 2013_reserve_parlementaire.csv | awk -F ";" '{print NF-1 }' | sort -n | uniq -c
9 -1
14106 0
En 2014, on aurait eu seulement 11 modifications de ligne à faire. C’est tellement stupide que je me demande si c’est pas fait exprès 🙁 .
1-Le premier point est que les fichiers JSON de 2013 et 2014 n’ont pas le même standard.
En 2013 le séparateur est simple cote ‘.
{
'Bénéficiaire' : '100% sport et loisirs',
'Adresse' : '',
'Descriptif' : 'Fonctionnement',
'Montant' : 1000.00,
'Nom' : 'CINIERI',
'Prénom' : 'Dino',
'Département' : 'Loire',
'Groupe' : 'UMP',
'Programme budgétaire' : '219-01',
'ID_Acteur' : 'PA267429'
},
En 2014 le séparateur est double cote : « .
{
"Bénéficiaire":"Télé Bocal",
"Adresse":"Maison des associations\n1/ ",
"Descriptif":"Mise ….",
"Montant":5000,
"Nom":"BAUPIN",
"Prénom":"Denis",
"Département":"Paris",
"Groupe":"Ecolo",
"Programme budgétaire":"313-03",
"ID_Acteur":"PA609016"
},
2-Par moment le Groupe est vide et il se trouve dans le nom, alors qu’il y a un champ Groupe.
{
'Bénéficiaire' : 'A.A.S.C.O.',
'Adresse' : '107 avenue Gabriel Péri - 93400 Saint-Ouen',
'Descriptif' : 'Fonctionnement',
'Montant' : 10000.00,
'Nom' : 'Groupe SRC',
'Prénom' : '',
'Département' : '*(non rattaché à un département)',
'Groupe' : '',
'Programme budgétaire' : '',
'ID_Acteur' : NULL
},
3-Par moment c’est trop NULL 🙁
{
'Bénéficiaire' : 'Club des plus belles baies du monde',
'Adresse' : '',
'Descriptif' : 'Fonctionnement',
'Montant' : 3000.00,
'Nom' : 'Groupe UMP',
'Prénom' : NULL,
'Département' : '*(non rattaché à un département)',
'Groupe' : NULL,
'Programme budgétaire' : '113-01',
'ID_Acteur' : NULL
},
Note : Si on recherche sur le site du Club des plus belles baies du monde, on trouve l’ex-Président Jérôme Bignon, qui semble être sénateur de la somme et UMP. Et ensuite le nouveau président Galip Gur (2012-2015). J’ai du mal à comprendre pourquoi Wikipédia parle de clientélisme 😉 . Et sur leur site ils font aussi la promotion de l’unité nationale :

j’arrête de me faire rire tout seul …
4-Par moment on a le prénom avec le nom.
{
'Bénéficiaire' : 'Commune de MECRIN ',
'Adresse' : '',
'Descriptif' : 'Aménagement de la place du général de Gaulle',
'Montant' : 10000.00,
'Nom' : 'PANCHER Bertrand',
'Prénom' : '',
'Département' : 'Meuse',
'Groupe' : 'UDI',
'Programme budgétaire' : '122-01',
'ID_Acteur' : 'PA333421'
},
...
{
'Bénéficiaire' : 'Commune de PETIT-LANDAU ',
'Adresse' : '',
'Descriptif' : 'Construction d’un centre technique communal et d’un centre de première intervention',
'Montant' : 40000.00,
'Nom' : 'HILLMEYER Francis',
'Prénom' : '',
'Département' : 'Haut-Rhin',
'Groupe' : 'UDI',
'Programme budgétaire' : '122-01',
'ID_Acteur' : 'PA216574'
},
5-Par moment on a des fautes dans le nom :
- Par exemple DE MAZIERES et DE MAZIèRE.
{
'Bénéficiaire' : 'Architect Tonic',
'Adresse' : '',
'Descriptif' : 'Fonctionnement',
'Montant' : 3000.00,
'Nom' : 'de MAZIÈRES',
'Prénom' : 'François',
'Département' : 'Yvelines',
'Groupe' : 'UMP',
'Programme budgétaire' : '150-13',
'ID_Acteur' : 'PA609345'
},
{
'Bénéficiaire' : 'ASP Yvelines',
'Adresse' : '',
'Descriptif' : 'Fonctionnement',
'Montant' : 3000.00,
'Nom' : 'DE MAZIERES',
'Prénom' : 'François',
'Département' : 'Yvelines',
'Groupe' : 'UMP',
'Programme budgétaire' : '204-11',
'ID_Acteur' : 'PA609345'
},
6- Pas très clair, si par exemple je cherche le nom et la somme de tous les députés qui ont mis de l’argent dans les alpes-maritimes :
$ cat 2014_reserve_parlementaire.json | awk -M -F":" '{if ($1 ~ /partement/) {nom = tolower($2); gsub(" ","_", nom); gsub (",","",montant); nom3 = nom2 "-" nom; gsub(",","",nom3); Groupe[nom3]+=montant; Nombre[nom3]++; if (Nombre[nom3] == 1) min[nom3] = montant; if ((montant - max[nom3]) > 0) max[nom3] = montant; if ((montant - min[nom3]) < 0) min[nom3] = montant; total += montant; nombre ++}; if ($1 ~ "Montant") {montant=$2; nom2 = "?"}; if ($1 ~ "Nom") {nom2=tolower($2)} } END {for (x in Groupe) { {if (x ~ /alpes-mar/) {printf ("%40s\t%ld\t%ld\t%ld\t%ld\t%ld\n",x,Groupe[x],Nombre[x],(Groupe[x]/Nombre[x]),min[x],max[x])}}} printf ("Total : \t\t\t\t %ld \t\t Nombre \t %d",total,nombre)}'
"salles"-"alpes-maritimes" 134330 84 1599 1000 13330
"brochand"-"alpes-maritimes" 84000 5 16800 8000 25500
"ginesy"-"alpes-maritimes" 108685 20 5434 687 60048
"ciotti"-"alpes-maritimes" 91000 42 2166 1000 20000
"guibal"-"alpes-maritimes" 121550 68 1787 1000 17000
"tabarot"-"alpes-maritimes" 106395 59 1803 1000 15000
"luca"-"alpes-maritimes" 119800 9 13311 8400 25000
"estrosi"-"alpes-maritimes" 110000 31 3548 1500 6000
"leonetti"-"alpes-maritimes" 150000 1 150000 150000 150000
Total : 80071558 Nombre 13133
J’observe par exemple que Ciotti n’a pas mis la totalité, et là j’ai du mal à comprendre :
-soit c’est parce qu’il n’a pas mis la totalité,
-soit c’est parce que c’est mis comme étant dans le Groupe, et son nom n’est donc pas présent. Dans ce cas il serait donc vraiment important de mettre le champ Groupe ailleurs que dans le nom quand c’est vu en tant que groupe. Voir même ajouter un booléen pour préciser l’information.
Si je cherche Ciotti ou Brochand ailleurs je ne vois rien …
$ cat 2014_reserve_parlementaire.json | awk -M -F":" '{if ($1 ~ /partement/) {nom = tolower($2); gsub(" ","_", nom); gsub (",","",montant); nom3 = nom2 "-" nom; gsub(",","",nom3); Groupe[nom3]+=montant; Nombre[nom3]++; if (Nombre[nom3] == 1) min[nom3] = montant; if ((montant - max[nom3]) > 0) max[nom3] = montant; if ((montant - min[nom3]) < 0) min[nom3] = montant; total += montant; nombre ++}; if ($1 ~ "Montant") {montant=$2; nom2 = "?"}; if ($1 ~ "Nom") {nom2=tolower($2)} } END {for (x in Groupe) { {if (x ~ /ciotti/) {printf ("%40s\t%ld\t%ld\t%ld\t%ld\t%ld\n",x,Groupe[x],Nombre[x],(Groupe[x]/Nombre[x]),min[x],max[x])}}} printf ("Total : \t\t\t\t %ld \t\t Nombre \t %d",total,nombre)}'
"ciotti"-"alpes-maritimes" 91000 42 2166 1000 20000
Total : 80071558 Nombre 13133
$ cat 2014_reserve_parlementaire.json | awk -M -F":" '{if ($1 ~ /partement/) {nom = tolower($2); gsub(" ","_", nom); gsub (",","",montant); nom3 = nom2 "-" nom; gsub(",","",nom3); Groupe[nom3]+=montant; Nombre[nom3]++; if (Nombre[nom3] == 1) min[nom3] = montant; if ((montant - max[nom3]) > 0) max[nom3] = montant; if ((montant - min[nom3]) < 0) min[nom3] = montant; total += montant; nombre ++}; if ($1 ~ "Montant") {montant=$2; nom2 = "?"}; if ($1 ~ "Nom") {nom2=tolower($2)} } END {for (x in Groupe) { {if (x ~ /brochand/) {printf ("%40s\t%ld\t%ld\t%ld\t%ld\t%ld\n",x,Groupe[x],Nombre[x],(Groupe[x]/Nombre[x]),min[x],max[x])}}} printf ("Total : \t\t\t\t %ld \t\t Nombre \t %d",total,nombre)}'
"brochand"-"alpes-maritimes" 84000 5 16800 8000 25500
Total : 80071558 Nombre 13133
7- Il faudrait qu’il soit marqué dans le fichier JSON le statut, à savoir :
- Parlementaire.
- Membre du bureau.
- Vice-président.
- Questeurs.
- Président de groupe.
- President de la commission.
- Président de l’assemblé.
C’est pas très clair, par moment on a Président de l’assemblée et pas moment on a Batolone.
_'bartolone', 520000 7 74285.7 195000.00, 6000.00, .. _'Présidence_de_l\'assemblée_nationale', 3117000 49 63612.2 1000.00, 90000.00,
En bref ce n’est pas un fichier propre … il faut le nettoyer soit même. Ce n’est pas impossible à faire mais ensuite une fois le fichier nettoyé il n’est plus certifié comme authentique vu que l’on a fait des modifications.
Bravo au site : http://demo.datarocks.io/reserve_parlementaire_2014/ qui a réussi à faire une exploitation des données. Sur le montant total il est marqué : 80 071 558 Euros, le même que dans mes calculs …. ouf !
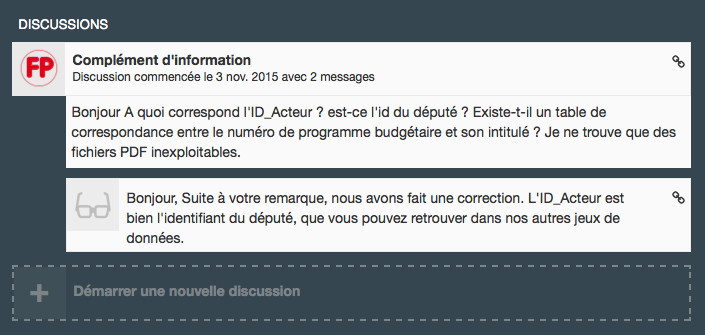
Je vais essayer de laisser un commentaire sur le site de Data.gouv.fr … si cela fonctionne. Car ma précédente discussion n’a pas fonctionné … et j’ai l’impression que le message du 3 novembre ne s’est affiché le 3 novembre mais bien après …
Un article sur les réserves parlementaires http://www.metronews.fr/info/video-transparence-faut-il-en-finir-avec-la-reserve-parlementaire-des-deputes/mpbu!BluCVQZllm5zU/ .
« Ce type de subvention est toujours intéressé. Il s’agit de faire plaisir à l’association locale », argumente le délégué général de l’association, Eudes Baufreton, auprès de metronews. « La Cour des comptes a démontré en outre que dans 40% des cas, les dossiers sélectionnés n’auraient pas dû faire l’objet d’une subvention. »
L’idéal serait donc la suppression avec au passage la suppression de 15% des parlementaires. Comme l’a proposé Alain Juppé : http://www.lefigaro.fr/politique/le-scan/citations/2014/10/23/25002-20141023ARTFIG00094-alain-juppe-veut-diviser-par-deux-le-nombre-de-parlementaires.php .
Mais tout cela n’est pas pour demain …