J’ai pas trouvé ce que cela signifiait :

Frédéric.

J’ai pas trouvé ce que cela signifiait :
Frédéric.
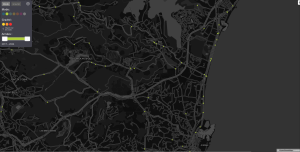
J’ai battu mon record : 3h40min53. L’organisation était moins bonne cette année, avec un parcours un peu long à la fin du marathon.
Le retour en train c’était un peu l’horreur cette année … 1h40 d’attente … un train était en panne. Pauvre service public.
Total distance: 42560 mDownload file: marathonalpesmaritimes2025.gpx
Max elevation: 36 m
Min elevation: 2 m
Total climbing: 320 m
Total descent: -322 m
Average speed: 11.65 km/h
Total time: 03:40:52
Voir : https://www.loicbertrand.eu/accidents/
Pour les vélos :
« La procédure de bornage judiciaire est toujours en cours. Le géomètre a demandé un complément de mission et doit refaire une visite de terrain. »
bref, c’est pas gagné … depuis 2022 et même avant. ( https://www.cyber-neurones.org/2022/08/biot-fermeture-du-circuit-du-terme-blanc-reunion-avec-lurbanisme/ )